
Videos
Highway crash data analysis. Researchers at Montana State University have written a tutorial on an empirical method for analyzing before and after highway crash data (Montana Department of Transportation, Research Report, May 2004). The initial step in the methodology is to develop a Safety Performance
Interstate Highways
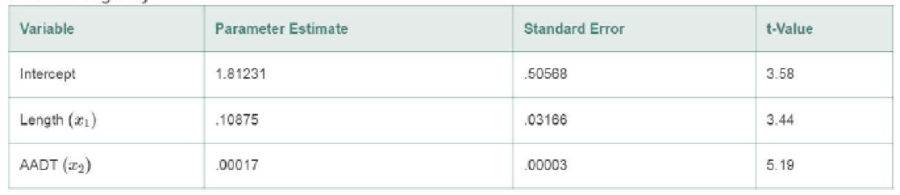
Noninterstate Highways
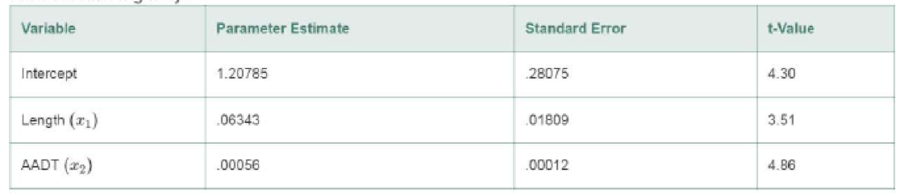
- a. Give the least squares prediction equation for the interstate highway model.
- b. Give practical interpretations of the β estimates, part a.
- c. Refer to part a. Find a 99% confidence interval for β1 and interpret the result.
- d. Refer to part a. Find a 99% confidence interval for β2 and interpret the result.
- e. Repeat parts a-d for the noninterstate highway model.
- f. Write a first-order model for E(y) as a function of x1 and x2 that allows the slopes to differ depending on whether the roadway segment is Interstate or non-interstate. [Hint: Create a dummy variable for Interstate/non-interstate.]
Want to see the full answer?
Check out a sample textbook solution
Chapter 12 Solutions
Statistics for Business and Economics (13th Edition)


- A survey of 581 citizens found that 313 of them favor a new bill introduced by the city. We want to find a 95% confidence interval for the true proportion of the population who favor the bill. What is the lower limit of the interval? Enter the result as a decimal rounded to 3 decimal digits. Your Answer:arrow_forward2. The SMSA data consisting of 141 observations on 10 variables is fitted by the model below: 1 y = Bo+B1x4 + ẞ2x6 + ẞ3x8 + √1X4X8 + V2X6X8 + €. See Question 2, Tutorial 3 for the meaning of the variables in the above model. The following results are obtained: Estimate Std. Error t value Pr(>|t|) (Intercept) 1.302e+03 4.320e+02 3.015 0.00307 x4 x6 x8 x4:x8 x6:x8 -1.442e+02 2.056e+01 -7.013 1.02e-10 6.340e-01 6.099e+00 0.104 0.91737 -9.455e-02 5.802e-02 -1.630 0.10550 2.882e-02 2.589e-03 11.132 1.673e-03 7.215e-04 2.319 F) x4 1 3486722 3486722 17.9286 4.214e-05 x6 1 14595537 x8 x4:x8 x6:x8 1 132.4836 < 2.2e-16 1045693 194478 5.3769 0.02191 1 1198603043 1198603043 6163.1900 < 2.2e-16 1 25765100 25765100 1045693 Residuals 135 26254490 Estimated variance matrix (Intercept) x4 x6 x8 x4:x8 x6:x8 (Intercept) x4 x6 x8 x4:x8 x6:x8 0.18875694 1.866030e+05 -5.931735e+03 -2.322825e+03 -16.25142055 0.57188953 -5.931735e+03 4.228816e+02 3.160915e+01 0.61621781 -0.03608028 -0.00445013 -2.322825e+03…arrow_forwardIn some applications the distribution of a discrete RV, X resembles the Poisson distribution except that 0 is not a possible value of X. Consider such a RV with PMF where 1 > 0 is a parameter, and c is a constant. (a) Find the expression of c in terms of 1. (b) Find E(X). (Hint: You can use the fact that, if Y ~ Poisson(1), the E(Y) = 1.)arrow_forward
- Suppose that X ~Bin(n,p). Show that E[(1 - p)] = (1-p²)".arrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forward
- This exercise is based on the following data on four bodybuilding supplements. (Figures shown correspond to a single serving.) Creatine(grams) L-Glutamine(grams) BCAAs(grams) Cost($) Xtend(SciVation) 0 2.5 7 1.00 Gainz(MP Hardcore) 2 3 6 1.10 Strongevity(Bill Phillips) 2.5 1 0 1.20 Muscle Physique(EAS) 2 2 0 1.00 Your personal trainer suggests that you supplement with at least 10 grams of creatine, 39 grams of L-glutamine, and 90 grams of BCAAs each week. You are thinking of combining Xtend and Gainz to provide you with the required nutrients. How many servings of each should you combine to obtain a week's supply that meets your trainer's specifications at the least cost? (If an answer does not exist, enter DNE.) servings of xtend servings of gainzarrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forward
- DATA TABLE VALUES Meal Price ($) 22.78 31.90 33.89 22.77 18.04 23.29 35.28 42.38 36.88 38.55 41.68 25.73 34.19 31.75 25.24 26.32 19.57 36.57 32.97 36.83 30.17 37.29 25.37 24.71 28.79 32.83 43.00 35.23 34.76 33.06 27.73 31.89 38.47 39.42 40.72 43.92 36.51 45.25 33.51 29.17 30.54 26.74 37.93arrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forwardSales personnel for Skillings Distributors submit weekly reports listing the customer contacts made during the week. A sample of 65 weekly reports showed a sample mean of 19.5 customer contacts per week. The sample standard deviation was 5.2. Provide 90% and 95% confidence intervals for the population mean number of weekly customer contacts for the sales personnel. 90% Confidence interval, to 2 decimals: ( , ) 95% Confidence interval, to 2 decimals:arrow_forward
 Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Linear Algebra: A Modern IntroductionAlgebraISBN:9781285463247Author:David PoolePublisher:Cengage Learning
Linear Algebra: A Modern IntroductionAlgebraISBN:9781285463247Author:David PoolePublisher:Cengage Learning Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning
Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning College AlgebraAlgebraISBN:9781305115545Author:James Stewart, Lothar Redlin, Saleem WatsonPublisher:Cengage Learning
College AlgebraAlgebraISBN:9781305115545Author:James Stewart, Lothar Redlin, Saleem WatsonPublisher:Cengage Learning