
Videos
Consider the following time series data:
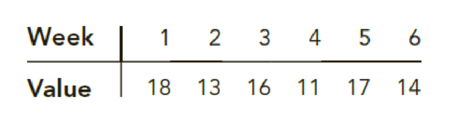
Using the naïve method (most recent value) as the forecast for the next week, compute the following measures of forecast accuracy:
- a.
Mean absolute error - b. Mean squared error
- c. Mean absolute percentage error
- d. What is the forecast for week 7?
(a)
Find the value of mean absolute error.
Answer to Problem 1P
The mean absolute error is 4.4.
Explanation of Solution
| Week | Time Series Value | Forecast | Forecast Error | Absolute Value of Forecast Error |
| 1 | 18 | |||
| 2 | 13 | 18 | −5 | 5 |
| 3 | 16 | 13 | 3 | 3 |
| 4 | 11 | 16 | −5 | 5 |
| 5 | 17 | 11 | 6 | 6 |
| 6 | 14 | 17 | −3 | 3 |
| Total | 22 |
Thus, the mean absolute error is 4.4.
(b)
Obtain the mean squared error.
Answer to Problem 1P
The mean squared error is 20.8.
Explanation of Solution
The mean squared error is obtained as given below:
| Absolute Value of Forecast Error | Squared Forecast Error |
| 5 | 25 |
| 3 | 9 |
| 5 | 25 |
| 6 | 36 |
| 3 | 9 |
| 22 | 104 |
Thus, the mean squared error is 20.8.
(c)
Find the mean absolute percentage error.
Answer to Problem 1P
The mean absolute percentage error is 31.88.
Explanation of Solution
The mean absolute percentage error is obtained is given below:
| Week | Time Series Value | Forecast | Forecast Error | Percentage Error | Absolute percentage Error |
| 1 | 18 | ||||
| 2 | 13 | 18 | −5 | −38.46 | 38.46 |
| 3 | 16 | 13 | 3 | 18.75 | 18.75 |
| 4 | 11 | 16 | −5 | −45.45 | 45.45 |
| 5 | 17 | 11 | 6 | 35.29 | 35.29 |
| 6 | 14 | 17 | −3 | −21.43 | 21.43 |
| Total | −51.30 | 159.38 |
Thus, the mean absolute percentage error is 31.88.
(d)
Obtain the forecast for week 7.
Answer to Problem 1P
The forecast for week 7 is 14.
Explanation of Solution
The forecast for week 7 is obtained as given below:
Thus, the forecast for week 7 is 14.
Want to see more full solutions like this?
Chapter 8 Solutions
Essentials of Business Analytics (MindTap Course List)


- A study was undertaken to compare respiratory responses of hypnotized and unhypnotized subjects. The following data represent total ventilation measured in liters of air per minute per square meter of body area for two independent (and randomly chosen) samples. Analyze these data using the appropriate non-parametric hypothesis test. Unhypnotized: 5.0 5.3 5.3 5.4 5.9 6.2 6.6 6.7 Hypnotized: 5.8 5.9 6.2 6.6 6.7 6.1 7.3 7.4arrow_forwardThe class will include a data exercise where students will be introduced to publicly available data sources. Students will gain experience in manipulating data from the web and applying it to understanding the economic and demographic conditions of regions in the U.S. Regions and topics of focus will be determined (by the student with instructor approval) prior to April. What data exercise can I do to fulfill this requirement? Please explain.arrow_forwardConsider the ceocomp dataset of compensation information for the CEO’s of 100 U.S. companies. We wish to fit aregression model to assess the relationship between CEO compensation in thousands of dollars (includes salary andbonus, but not stock gains) and the following variates:AGE: The CEOs age, in yearsEDUCATN: The CEO’s education level (1 = no college degree; 2 = college/undergrad. degree; 3 = grad. degree)BACKGRD: Background type(1= banking/financial; 2 = sales/marketing; 3 = technical; 4 = legal; 5 = other)TENURE: Number of years employed by the firmEXPER: Number of years as the firm CEOSALES: Sales revenues, in millions of dollarsVAL: Market value of the CEO's stock, in natural logarithm unitsPCNTOWN: Percentage of firm's market value owned by the CEOPROF: Profits of the firm, before taxes, in millions of dollars1) Create a scatterplot matrix for this dataset. Briefly comment on the observed relationships between compensationand the other variates.Note that companies with negative…arrow_forward
- 6 (Model Selection, Estimation and Prediction of GARCH) Consider the daily returns rt of General Electric Company stock (ticker: "GE") from "2021-01-01" to "2024-03-31", comprising a total of 813 daily returns. Using the "fGarch" package of R, outputs of fitting three GARCH models to the returns are given at the end of this question. Model 1 ARCH (1) with standard normal innovations; Model 2 Model 3 GARCH (1, 1) with Student-t innovations; GARCH (2, 2) with Student-t innovations; Based on the outputs, answer the following questions. (a) What can be inferred from the Standardized Residual Tests conducted on Model 1? (b) Which model do you recommend for prediction between Model 2 and Model 3? Why? (c) Write down the fitted model for the model that you recommended in Part (b). (d) Using the model recommended in Part (b), predict the conditional volatility in the next trading day, specifically trading day 814.arrow_forward4 (MLE of ARCH) Suppose rt follows ARCH(2) with E(rt) = 0, rt = ut, ut = στει, σε where {+} is a sequence of independent and identically distributed (iid) standard normal random variables. With observations r₁,...,, write down the log-likelihood function for the model esti- mation.arrow_forward5 (Moments of GARCH) For the GARCH(2,2) model rt = 0.2+0.25u1+0.05u-2 +0.30% / -1 +0.20% -2, find cov(rt). 0.0035 ut, ut = στει,στ =arrow_forward
- Definition of null hypothesis from the textbook Definition of alternative hypothesis from the textbook Imagine this: you suspect your beloved Chicken McNugget is shrinking. Inflation is hitting everything else, so why not the humble nugget too, right? But your sibling thinks you’re just being dramatic—maybe you’re just extra hungry today. Determined to prove them wrong, you take matters (and nuggets) into your own hands. You march into McDonald’s, get two 20-piece boxes, and head home like a scientist on a mission. Now, before you start weighing each nugget like they’re precious gold nuggets, let’s talk hypotheses. The average weight of nuggets as mentioned on the box is 16 g each. Develop your null and alternative hypotheses separately. Next, you weigh each nugget with the precision of a jeweler and find they average out to 15.5 grams. You also conduct a statistical analysis, and the p-value turns out to be 0.01. Based on this information, answer the following questions. (Remember,…arrow_forwardBusiness Discussarrow_forwardCape Fear Community Colle X ALEKS ALEKS - Dorothy Smith - Sec X www-awu.aleks.com/alekscgi/x/Isl.exe/10_u-IgNslkr7j8P3jH-IQ1w4xc5zw7yX8A9Q43nt5P1XWJWARE... Section 7.1,7.2,7.3 HW 三 Question 21 of 28 (1 point) | Question Attempt: 5 of Unlimited The proportion of phones that have more than 47 apps is 0.8783 Part: 1 / 2 Part 2 of 2 (b) Find the 70th The 70th percentile of the number of apps. Round the answer to two decimal places. percentile of the number of apps is Try again Skip Part Recheck Save 2025 Mcarrow_forward
- Hi, I need to sort out where I went wrong. So, please us the data attached and run four separate regressions, each using the Recruiters rating as the dependent variable and GMAT, Accept Rate, Salary, and Enrollment, respectively, as a single independent variable. Interpret this equation. Round your answers to four decimal places, if necessary. If your answer is negative number, enter "minus" sign. Equation for GMAT: Ŷ = _______ + _______ GMAT Equation for Accept Rate: Ŷ = _______ + _______ Accept Rate Equation for Salary: Ŷ = _______ + _______ Salary Equation for Enrollment: Ŷ = _______ + _______ Enrollmentarrow_forwardQuestion 21 of 28 (1 point) | Question Attempt: 5 of Unlimited Dorothy ✔ ✓ 12 ✓ 13 ✓ 14 ✓ 15 ✓ 16 ✓ 17 ✓ 18 ✓ 19 ✓ 20 = 21 22 > How many apps? According to a website, the mean number of apps on a smartphone in the United States is 82. Assume the number of apps is normally distributed with mean 82 and standard deviation 30. Part 1 of 2 (a) What proportion of phones have more than 47 apps? Round the answer to four decimal places. The proportion of phones that have more than 47 apps is 0.8783 Part: 1/2 Try again kip Part ی E Recheck == == @ W D 80 F3 151 E R C レ Q FA 975 % T B F5 10 の 000 园 Save For Later Submit Assignment © 2025 McGraw Hill LLC. All Rights Reserved. Terms of Use | Privacy Center | Accessibility Y V& U H J N * 8 M I K O V F10 P = F11 F12 . darrow_forwardYou are provided with data that includes all 50 states of the United States. Your task is to draw a sample of: 20 States using Random Sampling (2 points: 1 for random number generation; 1 for random sample) 10 States using Systematic Sampling (4 points: 1 for random numbers generation; 1 for generating random sample different from the previous answer; 1 for correct K value calculation table; 1 for correct sample drawn by using systematic sampling) (For systematic sampling, do not use the original data directly. Instead, first randomize the data, and then use the randomized dataset to draw your sample. Furthermore, do not use the random list previously generated, instead, generate a new random sample for this part. For more details, please see the snapshot provided at the end.) You are provided with data that includes all 50 states of the United States. Your task is to draw a sample of: o 20 States using Random Sampling (2 points: 1 for random number generation; 1 for random sample) o…arrow_forward
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill College Algebra (MindTap Course List)AlgebraISBN:9781305652231Author:R. David Gustafson, Jeff HughesPublisher:Cengage Learning
College Algebra (MindTap Course List)AlgebraISBN:9781305652231Author:R. David Gustafson, Jeff HughesPublisher:Cengage Learning Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning
Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning Trigonometry (MindTap Course List)TrigonometryISBN:9781305652224Author:Charles P. McKeague, Mark D. TurnerPublisher:Cengage Learning
Trigonometry (MindTap Course List)TrigonometryISBN:9781305652224Author:Charles P. McKeague, Mark D. TurnerPublisher:Cengage Learning