
Videos
a.
Construct a frequency bar graph for each city.
a.
Answer to Problem 35E
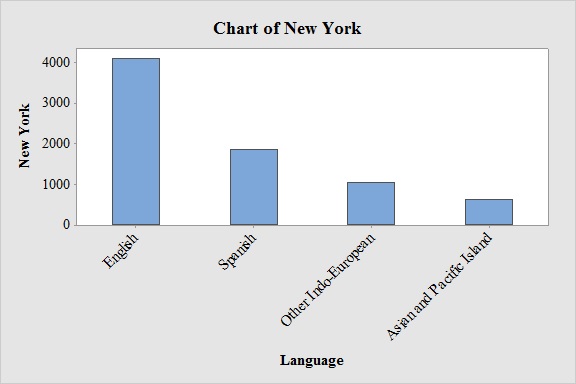
Output obtained from MINITAB software for New York is:
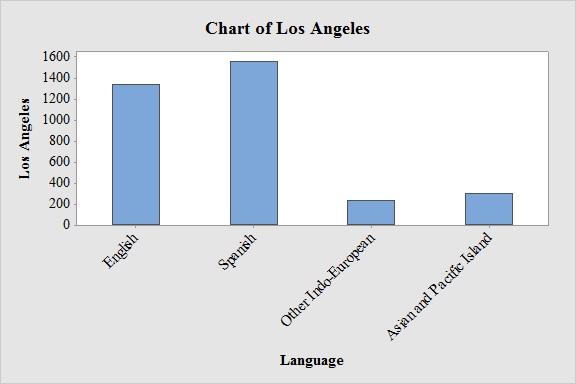
Output obtained from MINITAB software for Los Angeles is:
Explanation of Solution
Calculation:
The given information is a table representing the number of households categorized by the language spoken at home, for the cities of New York and Los Angeles in a recent year.
Software procedure:
- Step by step procedure to draw the bar chart for each city using MINITAB software.
- Choose Graph > Bar Chart.
- From Bars represent, choose unique values from table.
- Choose Simple.
- Click OK.
- In Graph variables, enter the column of New York and Los Angeles.
- In Categorical variables, enter the column of Language.
- Click OK
Observation:
From the bar graphs, it can be seen that the most frequently spoken language at home in New York and Los Angeles are English and Spanish respectively.
b.
Construct a frequency bar graph for the total.
b.
Answer to Problem 35E
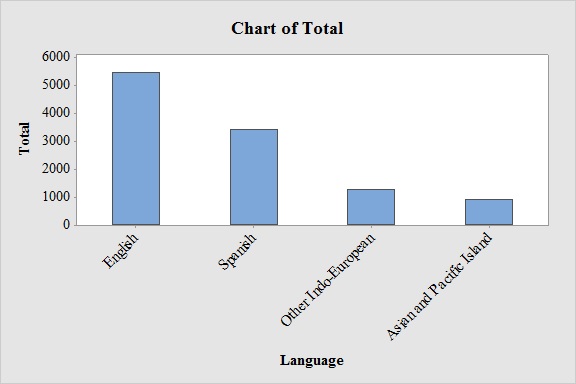
Output obtained from MINITAB software for Total is:
Explanation of Solution
Calculation:
Software procedure:
- Step by step procedure to draw the bar chart for each city using MINITAB software.
- Choose Graph > Bar Chart.
- From Bars represent, choose unique values from table.
- Choose Simple.
- Click OK.
- In Graph variables, enter the column of Total.
- In Categorical variables, enter the column of Language.
- Click OK
Observation:
From the bar graphs, it can be seen that the most frequently spoken language at home in both New York and Los Angeles is English.
c.
Construct a relative frequency bar graph for each city.
c.
Answer to Problem 35E
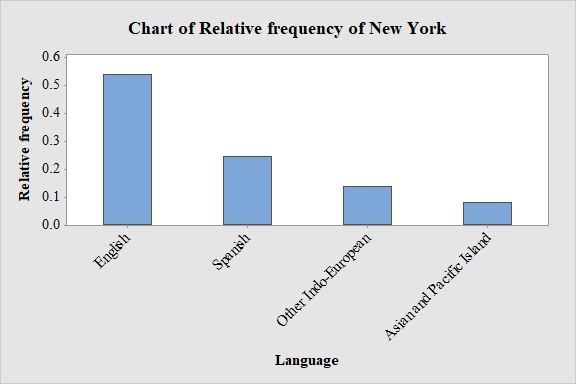
Output obtained from MINITAB software for New York is:
Output obtained from MINITAB software for Los Angeles is:
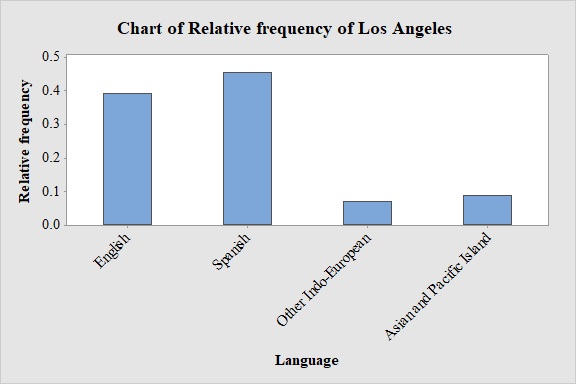
Explanation of Solution
Calculation:
Relative frequency for New York:
The general formula for the relative frequency is,
Therefore,
Similarly, the relative frequencies for New York is obtained below:
| Language | New York | Relative Frequency |
| English | 4,098 | |
| Spanish | 1,870 | |
| Other Indo-European | 1,037 | |
| Asian and Pacific Island | 618 |
Software procedure:
- Step by step procedure to draw the Bar chart for each city using MINITAB software.
- Choose Graph > Bar Chart.
- From Bars represent, choose unique values from table.
- Choose Simple.
- Click OK.
- In Graph variables, enter the column of Relative Frequency of New York
- In Categorical variables, enter the column of Language.
- Click OK
Observation:
From the graph, it can be seen that most probable spoken language at home in New York is English.
Relative frequency for Los Angeles:
Similarly, the relative frequencies for Los Angeles is obtained below:
| Language | Los Angeles | Relative Frequency |
| English | 1,339 | |
| Spanish | 1,555 | |
| Other Indo-European | 237 | |
| Asian and Pacific Island | 301 |
Software procedure:
- Step by step procedure to draw the Bar chart for Los Angeles using MINITAB software.
- Choose Graph > Bar Chart.
- From Bars represent, choose unique values from table.
- Choose Simple.
- Click OK.
- In Graph variables, enter the column of Relative Frequency of Los Angeles.
- In Categorical variables, enter the column of Language.
- Click OK
Observation:
From the graph, it can be seen that most probable spoken language at home in Los Angeles is Spanish.
d.
Construct a relative frequency bar graph for the total.
d.
Answer to Problem 35E
Output obtained from MINITAB software for Total is:
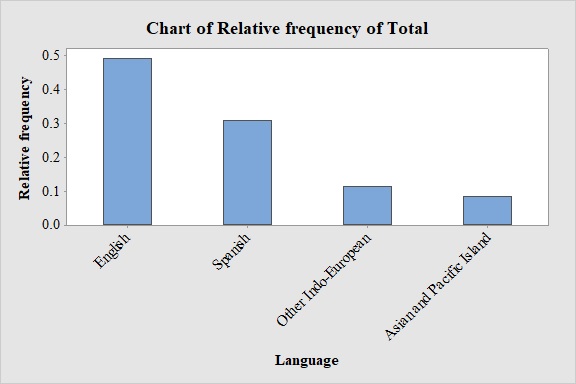
Explanation of Solution
Calculation:
Relative frequency for total:
The general formula for the relative frequency is,
Therefore,
Similarly, the relative frequencies for the total are obtained below:
| Language | Total | Relative Frequency |
| English | 5,437 | |
| Spanish | 3,425 | |
| Other Indo-European | 1,274 | |
| Asian and Pacific Island | 919 |
Software procedure:
- Step by step procedure to draw the Bar chart for total using MINITAB software.
- Choose Graph > Bar Chart.
- From Bars represent, choose unique values from table.
- Choose Simple.
- Click OK.
- In Graph variables, enter the column of Relative frequency of total.
- In Categorical variables, enter the column of Language.
- Click OK
Observation:
From the graph, it can be seen that most probable spoken language at home in both New York and Los Angeles is English.
e.
Explain the reason behind the heights of the bars for the frequency bar graph for the total are equal to the sums of the heights for the individual cities.
e.
Explanation of Solution
The total frequency represents the numbers of households in both cities combined. Therefore, the total frequency is the sum of the frequencies for New York and Los Angeles.
f.
Explain the reason behind the heights of the bars for the relative frequency bar graph for the total are not equal to the sums of the heights for the individual cities.
f.
Explanation of Solution
The relative frequency is the frequency divided by total frequency. The frequencies and total frequencies are different for each cities. Therefore, the relative frequency bar graph for the total are not equal to the sums of the heights for the individual cities.
Want to see more full solutions like this?
Chapter 2 Solutions
Essential Statistics


- You are provided with data that includes all 50 states of the United States. Your task is to draw a sample of: 20 States using Random Sampling (2 points: 1 for random number generation; 1 for random sample) 10 States using Systematic Sampling (4 points: 1 for random numbers generation; 1 for generating random sample different from the previous answer; 1 for correct K value calculation table; 1 for correct sample drawn by using systematic sampling) (For systematic sampling, do not use the original data directly. Instead, first randomize the data, and then use the randomized dataset to draw your sample. Furthermore, do not use the random list previously generated, instead, generate a new random sample for this part. For more details, please see the snapshot provided at the end.) You are provided with data that includes all 50 states of the United States. Your task is to draw a sample of: o 20 States using Random Sampling (2 points: 1 for random number generation; 1 for random sample) o…arrow_forwardCourse Home ✓ Do Homework - Practice Ques ✓ My Uploads | bartleby + mylab.pearson.com/Student/PlayerHomework.aspx?homeworkId=688589738&questionId=5&flushed=false&cid=8110079¢erwin=yes Online SP 2025 STA 2023-009 Yin = Homework: Practice Questions Exam 3 Question list * Question 3 * Question 4 ○ Question 5 K Concluir atualização: Ava Pearl 04/02/25 9:28 AM HW Score: 71.11%, 12.09 of 17 points ○ Points: 0 of 1 Save Listed in the accompanying table are weights (kg) of randomly selected U.S. Army male personnel measured in 1988 (from "ANSUR I 1988") and different weights (kg) of randomly selected U.S. Army male personnel measured in 2012 (from "ANSUR II 2012"). Assume that the two samples are independent simple random samples selected from normally distributed populations. Do not assume that the population standard deviations are equal. Complete parts (a) and (b). Click the icon to view the ANSUR data. a. Use a 0.05 significance level to test the claim that the mean weight of the 1988…arrow_forwardsolving problem 1arrow_forward
- select bmw stock. you can assume the price of the stockarrow_forwardThis problem is based on the fundamental option pricing formula for the continuous-time model developed in class, namely the value at time 0 of an option with maturity T and payoff F is given by: We consider the two options below: Fo= -rT = e Eq[F]. 1 A. An option with which you must buy a share of stock at expiration T = 1 for strike price K = So. B. An option with which you must buy a share of stock at expiration T = 1 for strike price K given by T K = T St dt. (Note that both options can have negative payoffs.) We use the continuous-time Black- Scholes model to price these options. Assume that the interest rate on the money market is r. (a) Using the fundamental option pricing formula, find the price of option A. (Hint: use the martingale properties developed in the lectures for the stock price process in order to calculate the expectations.) (b) Using the fundamental option pricing formula, find the price of option B. (c) Assuming the interest rate is very small (r ~0), use Taylor…arrow_forwardDiscuss and explain in the picturearrow_forward
- Bob and Teresa each collect their own samples to test the same hypothesis. Bob’s p-value turns out to be 0.05, and Teresa’s turns out to be 0.01. Why don’t Bob and Teresa get the same p-values? Who has stronger evidence against the null hypothesis: Bob or Teresa?arrow_forwardReview a classmate's Main Post. 1. State if you agree or disagree with the choices made for additional analysis that can be done beyond the frequency table. 2. Choose a measure of central tendency (mean, median, mode) that you would like to compute with the data beyond the frequency table. Complete either a or b below. a. Explain how that analysis can help you understand the data better. b. If you are currently unable to do that analysis, what do you think you could do to make it possible? If you do not think you can do anything, explain why it is not possible.arrow_forward0|0|0|0 - Consider the time series X₁ and Y₁ = (I – B)² (I – B³)Xt. What transformations were performed on Xt to obtain Yt? seasonal difference of order 2 simple difference of order 5 seasonal difference of order 1 seasonal difference of order 5 simple difference of order 2arrow_forward
- Calculate the 90% confidence interval for the population mean difference using the data in the attached image. I need to see where I went wrong.arrow_forwardMicrosoft Excel snapshot for random sampling: Also note the formula used for the last column 02 x✓ fx =INDEX(5852:58551, RANK(C2, $C$2:$C$51)) A B 1 No. States 2 1 ALABAMA Rand No. 0.925957526 3 2 ALASKA 0.372999976 4 3 ARIZONA 0.941323044 5 4 ARKANSAS 0.071266381 Random Sample CALIFORNIA NORTH CAROLINA ARKANSAS WASHINGTON G7 Microsoft Excel snapshot for systematic sampling: xfx INDEX(SD52:50551, F7) A B E F G 1 No. States Rand No. Random Sample population 50 2 1 ALABAMA 0.5296685 NEW HAMPSHIRE sample 10 3 2 ALASKA 0.4493186 OKLAHOMA k 5 4 3 ARIZONA 0.707914 KANSAS 5 4 ARKANSAS 0.4831379 NORTH DAKOTA 6 5 CALIFORNIA 0.7277162 INDIANA Random Sample Sample Name 7 6 COLORADO 0.5865002 MISSISSIPPI 8 7:ONNECTICU 0.7640596 ILLINOIS 9 8 DELAWARE 0.5783029 MISSOURI 525 10 15 INDIANA MARYLAND COLORADOarrow_forwardSuppose the Internal Revenue Service reported that the mean tax refund for the year 2022 was $3401. Assume the standard deviation is $82.5 and that the amounts refunded follow a normal probability distribution. Solve the following three parts? (For the answer to question 14, 15, and 16, start with making a bell curve. Identify on the bell curve where is mean, X, and area(s) to be determined. 1.What percent of the refunds are more than $3,500? 2. What percent of the refunds are more than $3500 but less than $3579? 3. What percent of the refunds are more than $3325 but less than $3579?arrow_forward
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt