
Videos
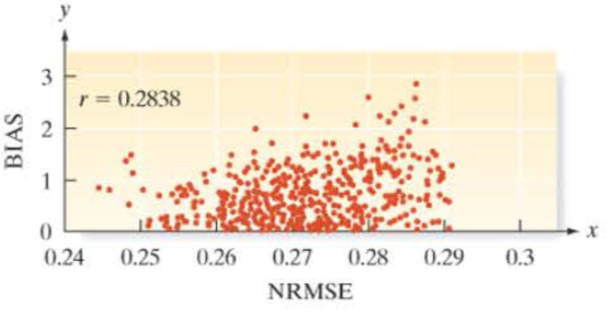
Evaluation of an imputation method for missing data. When analyzing big data (large data sets with many variables), business researchers often encounter the problem of missing data (e.g., non-response). Typically, an imputation method will be used to substitute in reasonable values (e.g., the
a. Conduct a test to determine if the true population correlation coefficient relating NRMSE and bias is positive. Interpret this result practically.
b. A
Want to see the full answer?
Check out a sample textbook solution
Chapter 11 Solutions
Statistics for Business and Economics (13th Edition)


- Joy's Frozen Yogurt shops have enjoyed rapid growth in northeastern states in recent years. From the analysis of Joy's various outlets, it was found that the demand curve follows this pattern: Q=200-300P+1201 +657-250A +400A; where Q = number of cups served per week P = average price paid for each cup I = per capita income in the given market (thousands) Taverage outdoor temperature A competition's monthly advertising expenditures (thousands) = A; = Joy's own monthly advertising expenditures (thousands) One of the outlets has the following conditions: P = 1.50, I = 10, T = 60, A₁ = 15, A; = 10 1. Estimate the number of cups served per week by this outlet. Also determine the outlet's demand curve. 2. What would be the effect of a $5,000 increase in the competitor's advertising expenditure? Illustrate the effect on the outlet's demand curve. 3. What would Joy's advertising expenditure have to be to counteract this effect?arrow_forwardThe Compute Company store has been selling its special word processing software, Aceword, during the last 10 months. Monthly sales and the price for Aceword are shown in the following table. Also shown are the prices for a competitive software, Goodwrite, and estimates of monthly family income. Calculate the appropriate elasticities, keeping in mind that you can calculate an elasticity measure only when all other factors do not change (using Excel). For example, price elasticities, months 1-2. Month Price Aceword Quantity Aceword Family Income Price Goodwrite 1 $120 200 $4,000 $130 21 120 210 4,000 145 3 120 220 4,200 145 4 110 240 4,200 145 90 5 115 230 4,200 145 6 115 215 4,200 125 10 7899 115 220 4,400 125 105 230 4,400 125 105 235 4,600 125 105 220 4,600 115arrow_forwardGordon Dividend Growth Model I downloaded some data about 3M (ticker MMM). Company 3M Ticker MMM Dividends Per Share 2017 $4.70 2018 $5.44 2019 $5.76 2020 $5.88 2021 $5.92 2022 $5.96 4. The dividend payment in 2022 was $5.96 per share. Based on the five-year history, we see that dividends per share grew at a compound annual growth rate of 4.86% $5.96 (1/5) CAGR = $4.70 − 1 = (1.2681)0.20 − 1 = 1.0486 - 1 = 0.0486 = 4.86% - - What should be the 2023 dividend based on these values?arrow_forward
- 4. The data set BWGHT.DTA contains data on births to women in the United States. Two variables of interest are the dependent variable, infant birth weight in ounces (bwght), and an explanatory variable, average number of cigarettes the mother smoked per day during pregnancy (cigs). The following simple regression was estimated using data on n=1,388 births: bwght=119.77 - .514 cigs (i) What is the predicted birth weight when cigs = 0? What about when cigs=20 (one pack per day)? Comment on the difference. (ii) Does this simple regression necessarily capture a causal relationship between the child's birth weight and the mother's smoking habits? Explain. (iii) To predict a birth weight of 125 ounces, what would cigs have to be? Comment. (iv) The proportion of women in the sample who do not smoke while pregnant is about .85. Does this help reconcile your finding from part (iii)?arrow_forwardGiven the demand equation Q following table (using Excel): = 1,500 200P, calculate all the numbers necessary to fill in the Elasticity P Q Point Arc Total Revenue Revenue Marginal $7.00 6.50 6.00 5.50 5.00 4.50 4.00 3.50 3.00 2.50arrow_forwardSuppose a firm has the following demand equation: where Q = quantity demanded P = product price (in dollars) Q=1,000 3,000P + 10A A = advertising expenditure (in dollars) Assume for the following questions that P =3$ and A = $2,000. 1. Suppose the firm dropped the price to $2.50. Would this be beneficial? Explain. Illustrate your answer with the use of a demand schedule and demand curve. 2. Suppose the firm raised the price to $4.00 while increasing its advertising expenditure by $100. Would this be beneficial? Explain. Illustrate your answer with the use of a demand schedule and a demand curve. (Hint: First construct the schedule and the curve assuming A = $2,000. Then construct the new schedule and curve assuming A = $2,100.)arrow_forward
- ABC Sports, a store that sells various types of sports clothing and other sports items, is planning to introduce a new design of Arizona Diamondbacks' baseball caps. A consultant has estimated the demand curve to be where Q is cap sales and P is price. Q=2,000 100P 1. How many caps could ABC sell at $6 each? 2. How much would the price have to be to sell 1,800 caps? 3. Suppose ABC were to use the caps as a promotion. How many caps could ABC give away free? 4. At what price would no caps be sold? 5. Calculate the point price elasticity of demand at a price of $6.arrow_forward1. What are the basic information related to the BPO industry in the Philippines? 2. Top 15 BPO industries here in the Philippines. 3. Significance to certain economies. 4. What services are being outsourced?arrow_forwardSelect a real-world case situation relevant to credit analysis and lending in Guyana. Use this case which you either know about already or have identified through research and address the following questions in essay format: i. Outline and discuss what “triggered” the regulatory body to intervene? ii. How effective do you think the response was to such a crisis? iii. Outline and discuss two ways that could be used to strengthen the current regulatory environment?arrow_forward
- Home can produce a maximum of 400 apples or a maximum of 600 bananas.Foreign can produce a maximum of 160 apples or a maximum of 800 bananas.(a) Graph and label Homes PPF. Label each axis and the slope. Use numbers.1(b) In the absence of trade, what is Homes autarky price of apples in terms of bananas?(c) Graph and label Foreigns production possibility frontier. Use numbers and label the slope.(d) Graph the world relative supply curve. Use numbers.23. (8 pts - RM) Now suppose world relative demand for apples takes the following form:Demand for apples/demand for bananas - price of bananas/price of apples. That is, RDA = Pbananas Papples(a) Graph the relative demand and relative supply curves on the world market diagram. Use numbers(b) What is the equilibrium (world) relative price of apples? (c) Show that both Home and Foreign gain from Trade and describe the pattern of trade.arrow_forwardA village has six residents, each of whom has accumulated savings of $100. Each villager can use this money either to buy a government bond that pays 18 percent interest per year or to buy a year-old llama, send it onto the commons to graze, and sell it after 1 year. The price the villager gets for the 2-year-old llama depends on the quality of the fleece It grows while grazing on the commons. That in turn depends on the animal's access to grazing, which depends on the number of llamas sent to the commons, as shown in the following table: Number of 11amas on the commons Price per 2- year-old 11ama ($) 1 125 2 119 3 116 4 113 5 6 111 109 The villagers make their investment decisions one after another, and their decisions are public. a. If each villager decides Individually how to Invest, how many llamas will be sent onto the commons, and what will be the resulting village Income? Number of llamas: [ 20 Instructions: Enter your response as a whole number. Village Income: $ 110 b. What is…arrow_forward5. Discrimination in the labor market The following table exhibits the name, gender, height, and minimum wage 10 people are willing to accept to work as travel nurses at a regional hospital. Name Gender Height Minimum Wage (Inches) (Dollars per week) Cho F 65 $297 Frances F 64 $316 Latasha F 68 $336 Dmitri M 70 $355 Jake M 71 $374 Rosa F 65 $393 Nick M 72 $420 Brian M 71 $439 Tim M 66 $451 Alyssa F 68 $478 The lowest weekly wage that the hospital can spend in order to hire five travel nurses is ________. Suppose the hiring director of the hospital prefers taller candidates because they think it will increase revenue, and so they impose a requirement that all newly hired travel nurses must have a height of at least 68 inches. With this mandate in place, the weekly wage rate the hospital now must pay in order to hire five travel nurses increases by ________.arrow_forward

 Managerial Economics: Applications, Strategies an...EconomicsISBN:9781305506381Author:James R. McGuigan, R. Charles Moyer, Frederick H.deB. HarrisPublisher:Cengage Learning
Managerial Economics: Applications, Strategies an...EconomicsISBN:9781305506381Author:James R. McGuigan, R. Charles Moyer, Frederick H.deB. HarrisPublisher:Cengage Learning Managerial Economics: A Problem Solving ApproachEconomicsISBN:9781337106665Author:Luke M. Froeb, Brian T. McCann, Michael R. Ward, Mike ShorPublisher:Cengage Learning
Managerial Economics: A Problem Solving ApproachEconomicsISBN:9781337106665Author:Luke M. Froeb, Brian T. McCann, Michael R. Ward, Mike ShorPublisher:Cengage Learning

