
Concept explainers
Videos
Residual Plot: Miles per Gallon Consider the data of Problem 9.
- (a) Make a residual plot for the least-squares model.
- (b) Use the residual plot to comment about the appropriateness of the least-squares model for these data. See Problem 19.
9. Weight of Car: Miles per Gallon Do heavier cars really use more gasoline? Suppose a car is chosen at random. Let x be the weight of the car (in hundreds of pounds), and let y be the miles per gallon (mpg). The following information is based on data taken from Consumer Reports (Vol. 62, No. 4).

Complete parts (a) through (e), given ∑x = 299, ∑y = 167, ∑x2 = 11,887, ∑y2 = 3773, ∑xy = 5814, and r ≈ –0.946.
(f) Suppose a car weighs x = 38 (hundred pounds). What does the least-squares line forecast for y = miles per gallon?
Expand Your Knowledge: Residual Plot The least-squares line usually does not go through all the sample data points (x, y). In fact, for a specified x value from a data pair (x, y), there is usually a difference between the predicted value and the y value paired with x. This difference is called the residual.
The residual is the difference between the y value in a specified data pair (x, y) and the value
One way to assess how well a least-squares line serves as a model for the data is a residual plot. To make a residual plot, we put the x values in order on the horizontal axis and plot the corresponding residuals
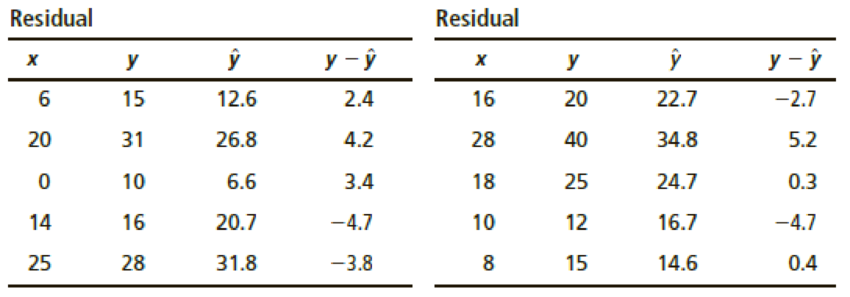
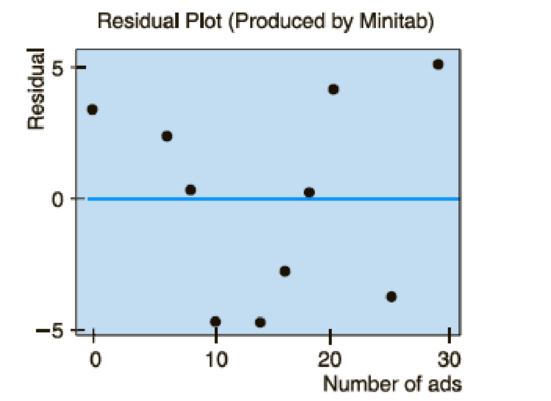
- (a) If the least-squares line provides a reasonable model for the data, the pattern of points in the plot will seem random and unstructured about the horizontal line at 0. Is this the case for the residual plot?
- (b) If a point on the residual plot seems far outside the pattern of other points, it might reflect an unusual data point (x, y), called an outlier. Such points may have quite an influence on the least-squares model. Do there appear to be any outliers in the data for the residual plot?
Want to see the full answer?
Check out a sample textbook solution
Chapter 9 Solutions
Bundle: Understandable Statistics: Concepts And Methods, 12th + Jmp Printed Access Card For Peck's Statistics + Webassign Printed Access Card For ... And Methods, 12th Edition, Single-term


- Techniques QUAT6221 2025 PT B... TM Tabudi Maphoru Activities Assessments Class Progress lIE Library • Help v The table below shows the prices (R) and quantities (kg) of rice, meat and potatoes items bought during 2013 and 2014: 2013 2014 P1Qo PoQo Q1Po P1Q1 Price Ро Quantity Qo Price P1 Quantity Q1 Rice 7 80 6 70 480 560 490 420 Meat 30 50 35 60 1 750 1 500 1 800 2 100 Potatoes 3 100 3 100 300 300 300 300 TOTAL 40 230 44 230 2 530 2 360 2 590 2 820 Instructions: 1 Corall dawn to tha bottom of thir ceraan urina se se tha haca nariad in archerca antarand cubmit Q Search ENG US 口X 2025/05arrow_forwardThe table below indicates the number of years of experience of a sample of employees who work on a particular production line and the corresponding number of units of a good that each employee produced last month. Years of Experience (x) Number of Goods (y) 11 63 5 57 1 48 4 54 45 3 51 Q.1.1 By completing the table below and then applying the relevant formulae, determine the line of best fit for this bivariate data set. Do NOT change the units for the variables. X y X2 xy Ex= Ey= EX2 EXY= Q.1.2 Estimate the number of units of the good that would have been produced last month by an employee with 8 years of experience. Q.1.3 Using your calculator, determine the coefficient of correlation for the data set. Interpret your answer. Q.1.4 Compute the coefficient of determination for the data set. Interpret your answer.arrow_forwardQ.3.2 A sample of consumers was asked to name their favourite fruit. The results regarding the popularity of the different fruits are given in the following table. Type of Fruit Number of Consumers Banana 25 Apple 20 Orange 5 TOTAL 50 Draw a bar chart to graphically illustrate the results given in the table.arrow_forward
- Q.2.3 The probability that a randomly selected employee of Company Z is female is 0.75. The probability that an employee of the same company works in the Production department, given that the employee is female, is 0.25. What is the probability that a randomly selected employee of the company will be female and will work in the Production department? Q.2.4 There are twelve (12) teams participating in a pub quiz. What is the probability of correctly predicting the top three teams at the end of the competition, in the correct order? Give your final answer as a fraction in its simplest form.arrow_forwardQ.2.1 A bag contains 13 red and 9 green marbles. You are asked to select two (2) marbles from the bag. The first marble selected will not be placed back into the bag. Q.2.1.1 Construct a probability tree to indicate the various possible outcomes and their probabilities (as fractions). Q.2.1.2 What is the probability that the two selected marbles will be the same colour? Q.2.2 The following contingency table gives the results of a sample survey of South African male and female respondents with regard to their preferred brand of sports watch: PREFERRED BRAND OF SPORTS WATCH Samsung Apple Garmin TOTAL No. of Females 30 100 40 170 No. of Males 75 125 80 280 TOTAL 105 225 120 450 Q.2.2.1 What is the probability of randomly selecting a respondent from the sample who prefers Garmin? Q.2.2.2 What is the probability of randomly selecting a respondent from the sample who is not female? Q.2.2.3 What is the probability of randomly…arrow_forwardTest the claim that a student's pulse rate is different when taking a quiz than attending a regular class. The mean pulse rate difference is 2.7 with 10 students. Use a significance level of 0.005. Pulse rate difference(Quiz - Lecture) 2 -1 5 -8 1 20 15 -4 9 -12arrow_forward
- The following ordered data list shows the data speeds for cell phones used by a telephone company at an airport: A. Calculate the Measures of Central Tendency from the ungrouped data list. B. Group the data in an appropriate frequency table. C. Calculate the Measures of Central Tendency using the table in point B. D. Are there differences in the measurements obtained in A and C? Why (give at least one justified reason)? I leave the answers to A and B to resolve the remaining two. 0.8 1.4 1.8 1.9 3.2 3.6 4.5 4.5 4.6 6.2 6.5 7.7 7.9 9.9 10.2 10.3 10.9 11.1 11.1 11.6 11.8 12.0 13.1 13.5 13.7 14.1 14.2 14.7 15.0 15.1 15.5 15.8 16.0 17.5 18.2 20.2 21.1 21.5 22.2 22.4 23.1 24.5 25.7 28.5 34.6 38.5 43.0 55.6 71.3 77.8 A. Measures of Central Tendency We are to calculate: Mean, Median, Mode The data (already ordered) is: 0.8, 1.4, 1.8, 1.9, 3.2, 3.6, 4.5, 4.5, 4.6, 6.2, 6.5, 7.7, 7.9, 9.9, 10.2, 10.3, 10.9, 11.1, 11.1, 11.6, 11.8, 12.0, 13.1, 13.5, 13.7, 14.1, 14.2, 14.7, 15.0, 15.1, 15.5,…arrow_forwardPEER REPLY 1: Choose a classmate's Main Post. 1. Indicate a range of values for the independent variable (x) that is reasonable based on the data provided. 2. Explain what the predicted range of dependent values should be based on the range of independent values.arrow_forwardIn a company with 80 employees, 60 earn $10.00 per hour and 20 earn $13.00 per hour. Is this average hourly wage considered representative?arrow_forward
- The following is a list of questions answered correctly on an exam. Calculate the Measures of Central Tendency from the ungrouped data list. NUMBER OF QUESTIONS ANSWERED CORRECTLY ON AN APTITUDE EXAM 112 72 69 97 107 73 92 76 86 73 126 128 118 127 124 82 104 132 134 83 92 108 96 100 92 115 76 91 102 81 95 141 81 80 106 84 119 113 98 75 68 98 115 106 95 100 85 94 106 119arrow_forwardThe following ordered data list shows the data speeds for cell phones used by a telephone company at an airport: A. Calculate the Measures of Central Tendency using the table in point B. B. Are there differences in the measurements obtained in A and C? Why (give at least one justified reason)? 0.8 1.4 1.8 1.9 3.2 3.6 4.5 4.5 4.6 6.2 6.5 7.7 7.9 9.9 10.2 10.3 10.9 11.1 11.1 11.6 11.8 12.0 13.1 13.5 13.7 14.1 14.2 14.7 15.0 15.1 15.5 15.8 16.0 17.5 18.2 20.2 21.1 21.5 22.2 22.4 23.1 24.5 25.7 28.5 34.6 38.5 43.0 55.6 71.3 77.8arrow_forwardIn a company with 80 employees, 60 earn $10.00 per hour and 20 earn $13.00 per hour. a) Determine the average hourly wage. b) In part a), is the same answer obtained if the 60 employees have an average wage of $10.00 per hour? Prove your answer.arrow_forward
 Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning
Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning Linear Algebra: A Modern IntroductionAlgebraISBN:9781285463247Author:David PoolePublisher:Cengage Learning
Linear Algebra: A Modern IntroductionAlgebraISBN:9781285463247Author:David PoolePublisher:Cengage Learning Algebra & Trigonometry with Analytic GeometryAlgebraISBN:9781133382119Author:SwokowskiPublisher:Cengage
Algebra & Trigonometry with Analytic GeometryAlgebraISBN:9781133382119Author:SwokowskiPublisher:Cengage
 College AlgebraAlgebraISBN:9781305115545Author:James Stewart, Lothar Redlin, Saleem WatsonPublisher:Cengage Learning
College AlgebraAlgebraISBN:9781305115545Author:James Stewart, Lothar Redlin, Saleem WatsonPublisher:Cengage Learning Algebra and Trigonometry (MindTap Course List)AlgebraISBN:9781305071742Author:James Stewart, Lothar Redlin, Saleem WatsonPublisher:Cengage Learning
Algebra and Trigonometry (MindTap Course List)AlgebraISBN:9781305071742Author:James Stewart, Lothar Redlin, Saleem WatsonPublisher:Cengage Learning