
Concept explainers
Videos
(a)
To find out what is the regression equation and what does the slope mean.
(a)
Answer to Problem 51E
The regression line is:
Explanation of Solution
In the question, the association between the high jump performance from the
| 800-m | High Jump |
| 134.15 | 1.91 |
| 135.92 | 1.76 |
| 132.27 | 1.85 |
| 135.32 | 1.7 |
| 131.31 | 1.79 |
| 135.21 | 1.76 |
| 133.62 | 1.85 |
| 137.01 | 1.82 |
| 137.72 | 1.79 |
| 133.23 | 1.7 |
| 137.28 | 1.67 |
| 130.77 | 1.82 |
| 140.05 | 1.85 |
| 133.69 | 1.7 |
| 137.9 | 1.79 |
| 133.95 | 1.85 |
| 138.68 | 1.73 |
| 137.65 | 1.79 |
| 138.47 | 1.7 |
| 145.1 | 1.67 |
| 133.08 | 1.76 |
| 134.57 | 1.79 |
| 142.58 | 1.73 |
| 132.27 | 1.7 |
| 141.21 | 1.7 |
| 145.68 | 1.7 |
Thus, we will create a regression line by using excel as:
We will first select the data given in the table and then go to the insert tab. In the tab we will use the
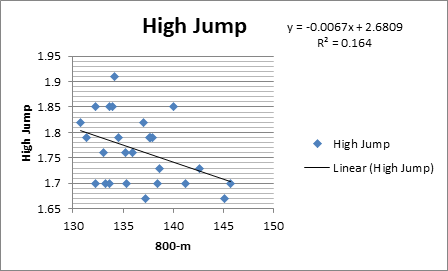
Thus, the regression line for this context is:
Thus, the slope of the line interprets that high jump height is lower, on average, by
(b)
To find out what percent of the variability in high jumps can be accounted for by differences in
(b)
Answer to Problem 51E
Explanation of Solution
In the question, the association between the high jump performance from the
Thus, from the above scatterplot in part (a) we can see that the coefficient of determination is also given, that is:
Thus, the value of
(c)
To explain do good high jumpers tend to be fast runners.
(c)
Answer to Problem 51E
Yes, good jumpers tend to be fast runners.
Explanation of Solution
In the question, the association between the high jump performance from the
Thus, we can say that good high jumpers tend to be fast runners because the slope is negative as calculated in part (a) and this implies faster runners tend to jump higher.
(d)
To explain what does the residuals plot reveal about the model.
(d)
Explanation of Solution
In the question, the association between the high jump performance from the
The residual plot is as:
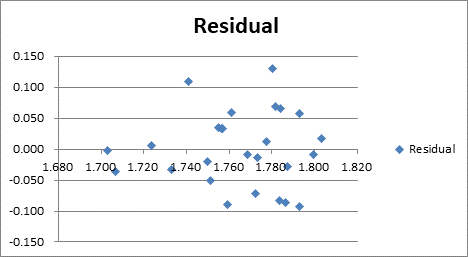
From the above residual plot we can see that there is slight tendency for less variation in high-jump height among the slower runners than among that faster ones.
(e)
To explain do you think this is a useful model and would you use it to predict high-jump performance.
(e)
Answer to Problem 51E
No, this is not useful model and it does not be used to predict high-jump performance.
Explanation of Solution
In the question, the association between the high jump performance from the
Thus, we think that this model is not especially useful model because the residual standard deviation is
Chapter 8 Solutions
Stats: Modeling the World Nasta Edition Grades 9-12
Additional Math Textbook Solutions
Elementary Statistics (13th Edition)
Introductory Statistics
Elementary Statistics: Picturing the World (7th Edition)
Elementary Statistics
College Algebra with Modeling & Visualization (5th Edition)
Calculus: Early Transcendentals (2nd Edition)


- Course Home ✓ Do Homework - Practice Ques ✓ My Uploads | bartleby + mylab.pearson.com/Student/PlayerHomework.aspx?homeworkId=688589738&questionId=5&flushed=false&cid=8110079¢erwin=yes Online SP 2025 STA 2023-009 Yin = Homework: Practice Questions Exam 3 Question list * Question 3 * Question 4 ○ Question 5 K Concluir atualização: Ava Pearl 04/02/25 9:28 AM HW Score: 71.11%, 12.09 of 17 points ○ Points: 0 of 1 Save Listed in the accompanying table are weights (kg) of randomly selected U.S. Army male personnel measured in 1988 (from "ANSUR I 1988") and different weights (kg) of randomly selected U.S. Army male personnel measured in 2012 (from "ANSUR II 2012"). Assume that the two samples are independent simple random samples selected from normally distributed populations. Do not assume that the population standard deviations are equal. Complete parts (a) and (b). Click the icon to view the ANSUR data. a. Use a 0.05 significance level to test the claim that the mean weight of the 1988…arrow_forwardsolving problem 1arrow_forwardselect bmw stock. you can assume the price of the stockarrow_forward
- This problem is based on the fundamental option pricing formula for the continuous-time model developed in class, namely the value at time 0 of an option with maturity T and payoff F is given by: We consider the two options below: Fo= -rT = e Eq[F]. 1 A. An option with which you must buy a share of stock at expiration T = 1 for strike price K = So. B. An option with which you must buy a share of stock at expiration T = 1 for strike price K given by T K = T St dt. (Note that both options can have negative payoffs.) We use the continuous-time Black- Scholes model to price these options. Assume that the interest rate on the money market is r. (a) Using the fundamental option pricing formula, find the price of option A. (Hint: use the martingale properties developed in the lectures for the stock price process in order to calculate the expectations.) (b) Using the fundamental option pricing formula, find the price of option B. (c) Assuming the interest rate is very small (r ~0), use Taylor…arrow_forwardDiscuss and explain in the picturearrow_forwardBob and Teresa each collect their own samples to test the same hypothesis. Bob’s p-value turns out to be 0.05, and Teresa’s turns out to be 0.01. Why don’t Bob and Teresa get the same p-values? Who has stronger evidence against the null hypothesis: Bob or Teresa?arrow_forward
- Review a classmate's Main Post. 1. State if you agree or disagree with the choices made for additional analysis that can be done beyond the frequency table. 2. Choose a measure of central tendency (mean, median, mode) that you would like to compute with the data beyond the frequency table. Complete either a or b below. a. Explain how that analysis can help you understand the data better. b. If you are currently unable to do that analysis, what do you think you could do to make it possible? If you do not think you can do anything, explain why it is not possible.arrow_forward0|0|0|0 - Consider the time series X₁ and Y₁ = (I – B)² (I – B³)Xt. What transformations were performed on Xt to obtain Yt? seasonal difference of order 2 simple difference of order 5 seasonal difference of order 1 seasonal difference of order 5 simple difference of order 2arrow_forwardCalculate the 90% confidence interval for the population mean difference using the data in the attached image. I need to see where I went wrong.arrow_forward
- Microsoft Excel snapshot for random sampling: Also note the formula used for the last column 02 x✓ fx =INDEX(5852:58551, RANK(C2, $C$2:$C$51)) A B 1 No. States 2 1 ALABAMA Rand No. 0.925957526 3 2 ALASKA 0.372999976 4 3 ARIZONA 0.941323044 5 4 ARKANSAS 0.071266381 Random Sample CALIFORNIA NORTH CAROLINA ARKANSAS WASHINGTON G7 Microsoft Excel snapshot for systematic sampling: xfx INDEX(SD52:50551, F7) A B E F G 1 No. States Rand No. Random Sample population 50 2 1 ALABAMA 0.5296685 NEW HAMPSHIRE sample 10 3 2 ALASKA 0.4493186 OKLAHOMA k 5 4 3 ARIZONA 0.707914 KANSAS 5 4 ARKANSAS 0.4831379 NORTH DAKOTA 6 5 CALIFORNIA 0.7277162 INDIANA Random Sample Sample Name 7 6 COLORADO 0.5865002 MISSISSIPPI 8 7:ONNECTICU 0.7640596 ILLINOIS 9 8 DELAWARE 0.5783029 MISSOURI 525 10 15 INDIANA MARYLAND COLORADOarrow_forwardSuppose the Internal Revenue Service reported that the mean tax refund for the year 2022 was $3401. Assume the standard deviation is $82.5 and that the amounts refunded follow a normal probability distribution. Solve the following three parts? (For the answer to question 14, 15, and 16, start with making a bell curve. Identify on the bell curve where is mean, X, and area(s) to be determined. 1.What percent of the refunds are more than $3,500? 2. What percent of the refunds are more than $3500 but less than $3579? 3. What percent of the refunds are more than $3325 but less than $3579?arrow_forwardA normal distribution has a mean of 50 and a standard deviation of 4. Solve the following three parts? 1. Compute the probability of a value between 44.0 and 55.0. (The question requires finding probability value between 44 and 55. Solve it in 3 steps. In the first step, use the above formula and x = 44, calculate probability value. In the second step repeat the first step with the only difference that x=55. In the third step, subtract the answer of the first part from the answer of the second part.) 2. Compute the probability of a value greater than 55.0. Use the same formula, x=55 and subtract the answer from 1. 3. Compute the probability of a value between 52.0 and 55.0. (The question requires finding probability value between 52 and 55. Solve it in 3 steps. In the first step, use the above formula and x = 52, calculate probability value. In the second step repeat the first step with the only difference that x=55. In the third step, subtract the answer of the first part from the…arrow_forward
 MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman