
Concept explainers
Videos
a)
To draw the model which shows 68-95-99.7
a)
Explanation of Solution
Given:
Following is the model which shows 68-95-99.7:
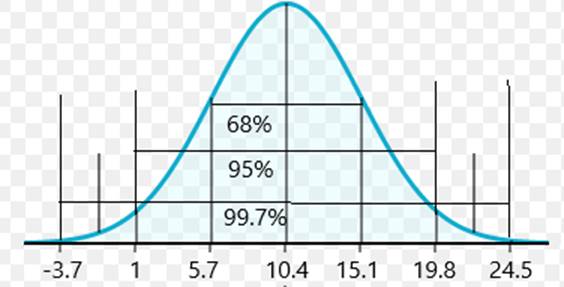
b)
To explain what size to be expected that central 95% of all trees.
b)
Answer to Problem 29E
An interval in which central 95% of trees to be found between 1 and 19.8
Explanation of Solution
Given:
According to rule of 68-95-99.7, the 95% of the values are within 2 standard deviation of the
Therefore,
Hence, interval in which central 95% of trees to be found between 1 and 19.8
c)
To find the percentage of trees that should be less than 1 inch in diameter.
c)
Answer to Problem 29E
The 2.5% of the trees are less than an inch in diameter.
Explanation of Solution
Given:
According to rule of 68-95-99.7, the 95% of the values are within 2 standard deviation of the mean.
Therefore,
That means, 1 inch is two standard deviations from the mean. According to rule, 95% of the data lies between 2 standard deviations from the mean. Since, total data is 100%, so 5% of the data is the more than 2 standard deviations from the mean. Therefore, as per symmetry, 2.5% is more than 2 standard deviations below the mean and 2.5% is more than 2 standard deviations above the mean.
Hence, approximately 2.5% of the trees are less than an inch in diameter.
d)
To find the percentage of trees that should be between 5.7 and 10.4 in diameter.
d)
Answer to Problem 29E
The 32% of the trees are between 5.7 and 10.4 an inch in diameter.
Explanation of Solution
Given:
According to rule of 68-95-99.7, the 68% of the values are within 1 standard deviation of the mean.
Therefore,
That means, 5.7 is one standard deviation below the mean.
Therefore, 100%-68% = 32% which is more than mean and less than 1 standard deviation of the mean. Therefore, 32% of the data lie between 5.7 and 10.4
e)
To find the percentage of trees that should be over 15 in diameter.
e)
Answer to Problem 29E
The 2.5% of the trees should over 15 inches in diameter.
Explanation of Solution
Given:
According to rule of 68-95-99.7, 15 is 2 standard deviation from the mean.
According to rule, 95% of the data lies between 2 standard deviations from the mean. Since, total data is 100%, so 5% of the data is the more than 2 standard deviations from the mean. Therefore, as per symmetry, 2.5% is more than 2 standard deviations below the mean and 2.5% is more than 2 standard deviations above the mean.
Hence, 2.5% of the trees should over 15 inches in diameter.
Chapter 6 Solutions
Stats: Modeling the World Nasta Edition Grades 9-12
Additional Math Textbook Solutions
Elementary Statistics
A First Course in Probability (10th Edition)
Calculus for Business, Economics, Life Sciences, and Social Sciences (14th Edition)
A Problem Solving Approach To Mathematics For Elementary School Teachers (13th Edition)
Calculus: Early Transcendentals (2nd Edition)


- The table below was compiled for a middle school from the 2003 English/Language Arts PACT exam. Grade 6 7 8 Below Basic 60 62 76 Basic 87 134 140 Proficient 87 102 100 Advanced 42 24 21 Partition the likelihood ratio test statistic into 6 independent 1 df components. What conclusions can you draw from these components?arrow_forwardWhat is the value of the maximum likelihood estimate, θ, of θ based on these data? Justify your answer. What does the value of θ suggest about the value of θ for this biased die compared with the value of θ associated with a fair, unbiased, die?arrow_forwardShow that L′(θ) = Cθ394(1 −2θ)604(395 −2000θ).arrow_forward
- a) Let X and Y be independent random variables both with the same mean µ=0. Define a new random variable W = aX +bY, where a and b are constants. (i) Obtain an expression for E(W).arrow_forwardThe table below shows the estimated effects for a logistic regression model with squamous cell esophageal cancer (Y = 1, yes; Y = 0, no) as the response. Smoking status (S) equals 1 for at least one pack per day and 0 otherwise, alcohol consumption (A) equals the average number of alcohoic drinks consumed per day, and race (R) equals 1 for blacks and 0 for whites. Variable Effect (β) P-value Intercept -7.00 <0.01 Alcohol use 0.10 0.03 Smoking 1.20 <0.01 Race 0.30 0.02 Race × smoking 0.20 0.04 Write-out the prediction equation (i.e., the logistic regression model) when R = 0 and again when R = 1. Find the fitted Y S conditional odds ratio in each case. Next, write-out the logistic regression model when S = 0 and again when S = 1. Find the fitted Y R conditional odds ratio in each case.arrow_forwardThe chi-squared goodness-of-fit test can be used to test if data comes from a specific continuous distribution by binning the data to make it categorical. Using the OpenIntro Statistics county_complete dataset, test the hypothesis that the persons_per_household 2019 values come from a normal distribution with mean and standard deviation equal to that variable's mean and standard deviation. Use signficance level a = 0.01. In your solution you should 1. Formulate the hypotheses 2. Fill in this table Range (-⁰⁰, 2.34] (2.34, 2.81] (2.81, 3.27] (3.27,00) Observed 802 Expected 854.2 The first row has been filled in. That should give you a hint for how to calculate the expected frequencies. Remember that the expected frequencies are calculated under the assumption that the null hypothesis is true. FYI, the bounderies for each range were obtained using JASP's drag-and-drop cut function with 8 levels. Then some of the groups were merged. 3. Check any conditions required by the chi-squared…arrow_forward
- Suppose that you want to estimate the mean monthly gross income of all households in your local community. You decide to estimate this population parameter by calling 150 randomly selected residents and asking each individual to report the household’s monthly income. Assume that you use the local phone directory as the frame in selecting the households to be included in your sample. What are some possible sources of error that might arise in your effort to estimate the population mean?arrow_forwardFor the distribution shown, match the letter to the measure of central tendency. A B C C Drag each of the letters into the appropriate measure of central tendency. Mean C Median A Mode Barrow_forwardA physician who has a group of 38 female patients aged 18 to 24 on a special diet wishes to estimate the effect of the diet on total serum cholesterol. For this group, their average serum cholesterol is 188.4 (measured in mg/100mL). Suppose that the total serum cholesterol measurements are normally distributed with standard deviation of 40.7. (a) Find a 95% confidence interval of the mean serum cholesterol of patients on the special diet.arrow_forward
- The accompanying data represent the weights (in grams) of a simple random sample of 10 M&M plain candies. Determine the shape of the distribution of weights of M&Ms by drawing a frequency histogram. Find the mean and median. Which measure of central tendency better describes the weight of a plain M&M? Click the icon to view the candy weight data. Draw a frequency histogram. Choose the correct graph below. ○ A. ○ C. Frequency Weight of Plain M and Ms 0.78 0.84 Frequency OONAG 0.78 B. 0.9 0.96 Weight (grams) Weight of Plain M and Ms 0.84 0.9 0.96 Weight (grams) ○ D. Candy Weights 0.85 0.79 0.85 0.89 0.94 0.86 0.91 0.86 0.87 0.87 - Frequency ☑ Frequency 67200 0.78 → Weight of Plain M and Ms 0.9 0.96 0.84 Weight (grams) Weight of Plain M and Ms 0.78 0.84 Weight (grams) 0.9 0.96 →arrow_forwardThe acidity or alkalinity of a solution is measured using pH. A pH less than 7 is acidic; a pH greater than 7 is alkaline. The accompanying data represent the pH in samples of bottled water and tap water. Complete parts (a) and (b). Click the icon to view the data table. (a) Determine the mean, median, and mode pH for each type of water. Comment on the differences between the two water types. Select the correct choice below and fill in any answer boxes in your choice. A. For tap water, the mean pH is (Round to three decimal places as needed.) B. The mean does not exist. Data table Тар 7.64 7.45 7.45 7.10 7.46 7.50 7.68 7.69 7.56 7.46 7.52 7.46 5.15 5.09 5.31 5.20 4.78 5.23 Bottled 5.52 5.31 5.13 5.31 5.21 5.24 - ☑arrow_forwardく Chapter 5-Section 1 Homework X MindTap - Cengage Learning x + C webassign.net/web/Student/Assignment-Responses/submit?pos=3&dep=36701632&tags=autosave #question3874894_3 M Gmail 品 YouTube Maps 5. [-/20 Points] DETAILS MY NOTES BBUNDERSTAT12 5.1.020. ☆ B Verify it's you Finish update: All Bookmarks PRACTICE ANOTHER A computer repair shop has two work centers. The first center examines the computer to see what is wrong, and the second center repairs the computer. Let x₁ and x2 be random variables representing the lengths of time in minutes to examine a computer (✗₁) and to repair a computer (x2). Assume x and x, are independent random variables. Long-term history has shown the following times. 01 Examine computer, x₁₁ = 29.6 minutes; σ₁ = 8.1 minutes Repair computer, X2: μ₂ = 92.5 minutes; σ2 = 14.5 minutes (a) Let W = x₁ + x2 be a random variable representing the total time to examine and repair the computer. Compute the mean, variance, and standard deviation of W. (Round your answers…arrow_forward
 MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman