
Concept explainers
Videos
(a)
The
(a)
Answer to Problem 23P
Solution: The provided values, that is,
Explanation of Solution
Given: The provided table consists of values of x and y, where x represents the average annual hours spent by a person in traffic delay, y represents the average annual gallons of fuel wasted per person due to traffic delay. The data consists of 8 data pairs, thus n is 8.
Calculation: Follow the steps given below in MS Excel to obtain the scatter plot of the data.
Step 1: Enter the data into an MS Excel sheet. The screenshot is given below.
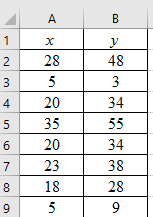
Step 2: Select the data and click on ‘Insert’. Go to charts and select the chart type ‘Scatter’.
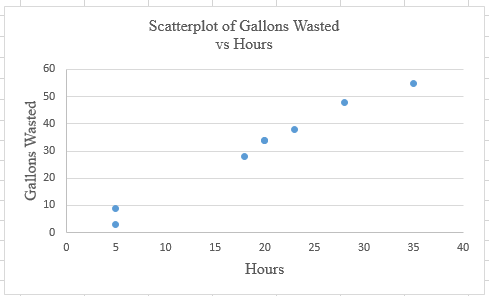
Step 3: Select the first plot and then click ‘add chart element’ provided in the left corner of the menu bar. Insert the ‘Axis titles’ and ‘Chart title’. The scatter plot for the provided data is shown below:
To calculate
| 28 | 48 | 784 | 2304 | 1344 |
| 5 | 3 | 25 | 9 | 15 |
| 20 | 34 | 400 | 1156 | 680 |
| 35 | 55 | 1225 | 3025 | 1925 |
| 20 | 34 | 400 | 1156 | 680 |
| 23 | 38 | 529 | 1444 | 874 |
| 18 | 28 | 324 | 784 | 504 |
| 5 | 9 | 25 | 81 | 45 |
The provided values,
Now, the value of
Substituting the values in the above formula. Thus:
Therefore, the correlation coefficient is 0.991.
(b)
The averages
(b)
Answer to Problem 23P
Solution: The values for data set 1 are
The values for data set 2 are
Explanation of Solution
Given: The provided table consists of values of x and y, where x represents the average annual hours spent by a person in traffic delay, y represents the average annual gallons of fuel wasted per person due to traffic delay.
The second table consists of x and y values where, x represent the annual hours lost by a person spent in traffic delay, y represents the annual gallons of fuel wasted by that person in traffic delay.
The data sets consist of 8 data pairs, thus n is 8 for both the data sets.
The provided values of data set 1 are,
The provided values of data set 2 are,
Calculation:
The value of
The value of
The standard deviation of x for data set 1 can be calculated as,
The standard deviation of
The value of
The value of
The standard deviation of
The standard deviation of
For the second data set, that is, for the variables based on single individuals, the standard deviations
The values
(c)
The scatter plot, whether the provided values of
(c)
Answer to Problem 23P
Solution: The provided values, that is,
Explanation of Solution
The provided table consists of values of x and y, where x represents the average annual hours spent by a person in traffic delay, y represents the average annual gallons of fuel wasted per person due to traffic delay.
The data sets consist of 8 data pairs, thus n is 8.
Calculation: Follow the steps given below in MS Excel to obtain the scatter plot of the data.
Step 1: Enter the data into an MS Excel sheet. The screenshot is given below.
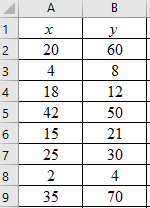
Step 2: Select the data and click on ‘Insert’. Go to charts and select the chart type ‘Scatter’.
Step 3: Select the first plot and then click ‘add chart element’ provided in the left corner of the menu bar. Insert the ‘Axis titles’ and ‘Chart title’. The scatter plot for the provided data is shown below:
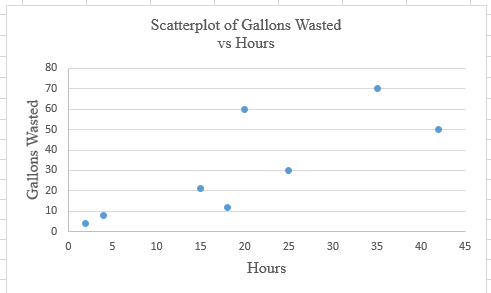
Calculation: The calculation for
| 20 | 60 | 400 | 3600 | 1200 |
| 4 | 8 | 16 | 64 | 32 |
| 18 | 12 | 324 | 144 | 216 |
| 42 | 50 | 1764 | 2500 | 2100 |
| 15 | 21 | 225 | 441 | 315 |
| 25 | 30 | 625 | 900 | 750 |
| 2 | 4 | 4 | 16 | 8 |
| 35 | 70 | 1225 | 4900 | 2450 |
The provided values,
Now, the value of
Substituting the values in the above formula. Thus:
Therefore, the correlation coefficient is 0.794.
(d)
Comparison between the values of r that are calculated in part (a) and part (c), whether the data for average have a higher correlation coefficient than the data for individual measurement or not, and the reason for it.
(d)
Answer to Problem 23P
Solution: Yes, the data for average has a higher correlation coefficient than the data for individual measurement because, according to the central limit theorem, the standard deviation of averages will be smaller than the standard deviation of individual values.
Explanation of Solution
Given: The values of correlation coefficient from part (a) and part (b) are 0.991 and 0.794, respectively.
It can be seen that
According to the central limit theorem, the standard deviation is smaller for the
Want to see more full solutions like this?
Chapter 4 Solutions
Student Solutions Manual for Brase/Brase's Understanding Basic Statistics, 7th


- This is the information about the actors who won the Best Actor Oscar: Best actors 44 41 62 52 41 34 34 52 41 37 38 34 32 40 43 56 41 39 49 57 35 30 39 41 44 41 38 42 52 51 49 35 47 31 47 37 57 42 45 42 44 62 43 42 48 49 56 38 60 30 40 42 36 76 39 53 45 36 62 43 51 32 42 54 52 37 38 32 45 60 46 40 36 47 29 43 a. What is the variable? What type? b. Construct an interval-frequency table, with columns containing: class mark, absolute frequency, relative frequency, cumulative frequency, cumulative relative frequency, and percentage frequency.arrow_forwardans c plsarrow_forwardCritically analyze the following graph and, based on statistical information, indicate the type of error it presents IN NO MORE THAN 3 LINES SCOTCEN POLL OF POLLS SHOULD SCOTLAND BE INDEPENDENT? NO 52% YES 58% LIVE CAW NAS & 28.30 HAS KILLED MORE THAN 2,600 IN WEST AFRICA, WORLD HEALTH ORG. BROOKEBCNNarrow_forward
- Critically analyze the following graph and, based on statistical information, indicate the type of error it presents IN NO MORE THAN 3 LINES PRESIDENTIAL PREFERENCES RODOLFO CARTER 3% (+2pts) EVELYN MATTHEI 22% (+6pts) With the exception of President Boric, could you tell me who you would like to be the next president of Chile? CAMILA VALLEJO 4% (+2pts) JOSÉ ANTONIO KAST 19% (+5pts) MICHELLE BACHELET 6% (+1pts)arrow_forwardCritically analyze the following graph and, based on statistical information, indicate the type of error it presents IN NO MORE THAN 3 LINES 13% APPROVE 4% DOESN'T KNOW DOESN'T RESPOND 5% NEITHER APPROVES NOR DISAPPROVES 78% DISAPPROVES SURVEY PRESIDENTIAL APPROVAL DROPS TO 13%arrow_forwardPlease help with this following question I'm not too sure if question (a) and (b) are correct and not sure how to calculate (c) The csv data is below "","New","Current" "1","67",66 "2","77",73 "3","76",73 "4","76",76 "5","77",79 "6","84",76 "7","71",78 "8","84",72 "9","73",76 "10","71",73 "11","72",77 "12","70",72 "13","75",72 "14","84",71 "15","77",73 "16","65",72 "17","69",73 "18","71",73 "19","79",71 "20","75",78 "21","76",69 "22","73",74 "23","76",71 "24","64",74 "25","81",78 "26","79",76 "27","70",77 "28","79",71 "29","84",73 "30","79",69 "31","69",72 "32","81",76 "33","77",70 "34","77",71 "35","71",69 "36","67",72 "37","70",76 "38","77",73 "39","82",73 "40","72",73arrow_forward
- Please help me answer the following question(c) A previous study found that 15% of nurses reported participating in mental health support programs.From the 96% found in (b) , can you conclude that proportion of nurses reported participating in mental health support programs p(current), has changed from the previous study?(Yes/No) because the confidence interval in (b) (captures/does not capture) 15%.(d) Refer to your answer in (b) : The Alberta Nurses Association expects that not more than 23 % of nurses will participate in the survey on mental health support programs. Given the result in part (b) can we conclude that this expectation is reasonable?(Yes/No) because the (upper bound/lower bound) of the 96% confidence interval is (less than/not less than/greater than) 23%. The Alberta Nursing Association conducts an annual survey to estimate the proportion of nurses who participate in mental health support programs. The most recent application of this survey involved a random sample of…arrow_forwardPlease help me solve this questionThis is what was in the csv file:"","Diabetic","Heart Disease""1",32644,30646"2",789,1670"3",12802,36274"4",2177,5011"5",1910,3300"6",3320,4256"7",61425,39053"8",19768,28635"9",19502,39546"10",5642,12182"11",107864,152098"12",29918,60433"13",2397,3550"14",41559,34705"15",49169,57948"16",72853,83100"17",2155,2873"18",140220,134517"19",28181,26212"20",18850,38637"21",69564,68582"22",13897,12613"23",6868,9138"24",9735,4767"25",12102,13447"26",36571,50010"27",44665,55141"28",26620,33970"29",25525,29766"30",14167,20206Q(b) From this, the relationship between these two variables is (non-existent/positive/negative) . I can categorize this relationship as being (strong/weak/moderate).Q(c) Drop down is (+/-)Q(d) Drop downs in order are __% of the (average/median/variation/standard deviation) in the (the number of people diagnosed with heart disease/the number of people diagnosed with diabetes)−variable can be explained by its (linear relationship/relationship)…arrow_forwardPlease help me answer the following question The drop down for question (e, f, and g) is (YES/NO) Based on the P-value above, the assumption of equal variances among the four machines (Is Met/Is Not Met) Based on the data, the average fill for machine 3 is (statistically lower than/statistically higher than/the same as/not statistically different than/statistically different than/Hard to say then when comparing to/Refuse to say when comparing to) machine 1.arrow_forward
- Business Discussarrow_forward1 for all k, and set o (ii) Let X1, X2, that P(Xkb) = x > 0. Xn be independent random variables with mean 0, suppose = and Var Xk. Then, for 0x) ≤2 exp-tx+121 Στ k=1arrow_forwardLemma 1.1 Suppose that g is a non-negative, non-decreasing function such that E g(X) 0. Then, E g(|X|) P(|X|> x) ≤ g(x)arrow_forward
 Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt