
Concept explainers
Videos
a.
Find whether there is a difference in the variation in team salary among the people from Country A and National league teams.
a.
Answer to Problem 50DE
There is no difference in the variance in team salary among the people from Country A and National league teams.
Explanation of Solution
The null and alternative hypotheses are stated below:
Null hypothesis: There is no difference in the variance in team salary among Country A and National league teams.
Alternative hypothesis: There is difference in the variance in team salary among Country A and National league teams.
Step-by-step procedure to obtain the test statistic using Excel:
- In the first column, enter the salaries of Country A’s team.
- In the second column, enter the salaries of National team.
- Select the Data tab on the top menu.
- Select Data Analysis and Click on: F-Test, Two-sample for variances and then click on OK.
- In the dialog box, select Input
Range . - Click OK
Output obtained using Excel is represented as follows:
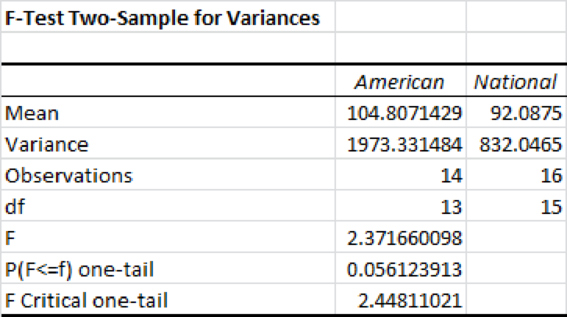
From the above output, the F- test statistic value is 2.37 and its p-value is 0.056.
Decision Rule:
If the p-value is less than the level of significance, reject the null hypothesis. Otherwise, fail to reject the null hypothesis.
Conclusion:
The significance level is 0.05. The p-value is 0.056 and it is greater than the significance level. The null hypothesis is rejected at the 0.05 significance level.
Thus, there is no difference in the variance in team salary among Country A and National league teams.
b.
Create a variable that classifies a team’s total attendance into three groups.
Find whether there is a difference in the
b.
Answer to Problem 50DE
There is no difference in the mean number of games won among the three groups.
Explanation of Solution
Let X represent the total attendance into three groups. Samples 1, 2, and 3 are “less than 2 (million)”, 2 up to 3, and 3 or more attendance of teams of three groups, respectively.
The following table gives the number of games won by the three groups of attendances.
| Sample 1 | Sample 2 | Sample 3 |
| 85 | 81 | 69 |
| 68 | 94 | 88 |
| 55 | 93 | 89 |
| 72 | 61 | 86 |
| 94 | 97 | 74 |
| 75 | 64 | 81 |
| 69 | 94 | |
| 83 | 88 | |
| 66 | 93 | |
| 95 | ||
| 79 | ||
| 76 | ||
| 73 | ||
| 98 |
The null and alternative hypotheses are as follows:
Null hypothesis: There is no difference in the mean number of games won among the three groups.
Alternative hypothesis: There is a difference in the mean number of games won among the three groups
Step-by-step procedure to obtain the test statistic using Excel:
- In Sample 1, enter the number of games won by the team, which is less than 2 million attendances.
- In Sample 2, enter the number of games won by the team of 2 up to 3 million attendances.
- In Sample 3, enter the number of games won by the team of 3 or more million attendances.
- Select the Data tab on the top menu.
- Select Data Analysis and Click on: ANOVA: Single factor and then click on OK.
- In the dialog box, select Input Range.
- Click OK
Output obtained using Excel is represented as follows:
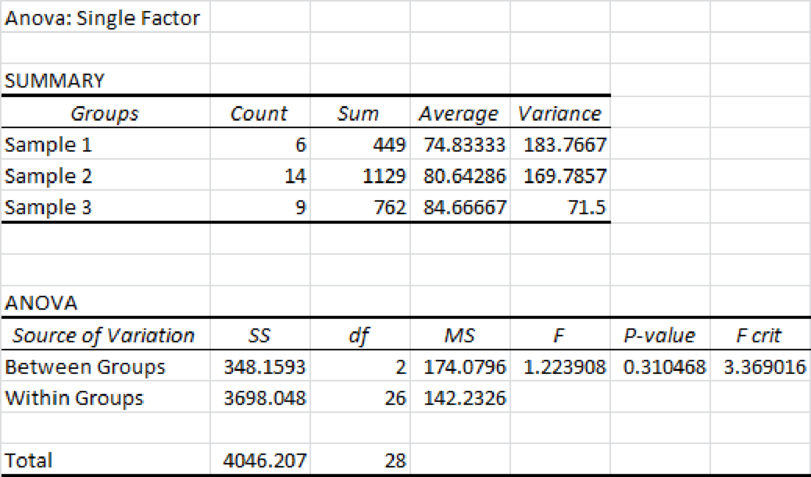
From the above output, the F test statistic value is 1.22 and the p-value is 0.31.
Conclusion:
The level of significance is 0.05. The p-value is greater than the significance level. Hence, one can fail to reject the null hypothesis at the 0.05 significance level. Thus, there is no difference in the mean number of games won among the three groups.
c.
Find whether there is a difference in the mean number of home runs hit per team using the variable defined in Part b.
c.
Answer to Problem 50DE
There is no difference in the mean number of home runs hit per team.
Explanation of Solution
The null and alternative hypotheses are stated below:
Null hypothesis: There is no difference in the mean number of home runs hit per team.
Alternative hypothesis: There is a difference in the mean number of home runs hit per team.
The following table gives the number of home runs per each team, which is defined in Part b.
| Sample 1 | Sample 2 | Sample 3 |
| 211 | 165 | 165 |
| 136 | 149 | 163 |
| 146 | 214 | 187 |
| 131 | 137 | 116 |
| 195 | 172 | 245 |
| 149 | 166 | 158 |
| 175 | 137 | 103 |
| 202 | 159 | |
| 131 | 200 | |
| 139 | ||
| 170 | ||
| 121 | ||
| 198 | ||
| 194 |
Step-by-step procedure to obtain the test statistic using Excel:
- In Sample 1, enter the number of home runs hit by the group of less than 2 million attendances.
- In Sample 2, enter the number of home runs hit by the group of 2 up to 3 million attendances.
- In Sample 3, enter the number of home runs hit by the group of 3 or more million attendances.
- Select the Data tab on the top menu.
- Select Data Analysis and Click on: ANOVA: Single factor and then click on OK.
- In the dialog box, select Input Range.
- Click OK
Output obtained using Excel is represented as follows:
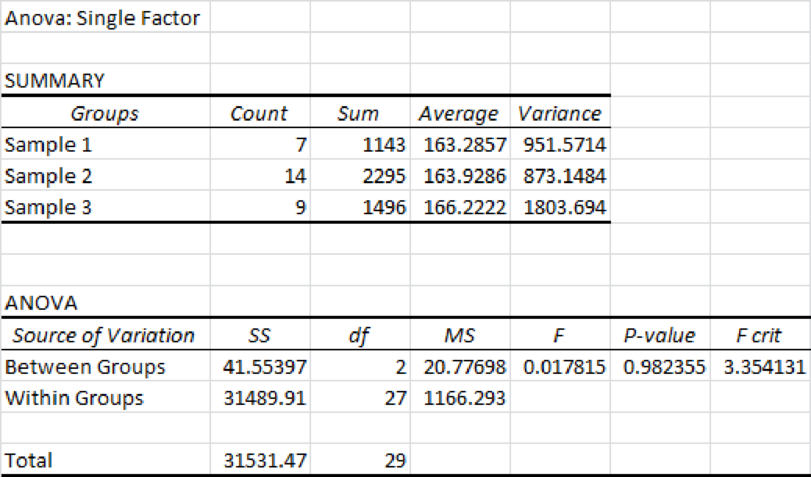
From the above output, the F test statistic value is 0.018 and the p-value is 0.9823.
Conclusion:
The level of significance is 0.05 and the p-value is greater than the significance level. Hence, one fails to reject the null hypothesis at the 0.05 significance level. Thus, there is no difference in the mean number of home runs hit per team.
d.
Find whether there is a difference in the mean salary of the three groups.
d.
Answer to Problem 50DE
The mean salaries are different for each group.
Explanation of Solution
The null and alternative hypotheses are stated below:
Null hypothesis: The mean salary of the three groups is equal.
Alternative hypothesis: At least one mean salary is different from other.
The following table provides the salary of each group that is defined in Part b.
| Sample 1 | Sample 2 | Sample 3 |
| 96.9 | 74.3 | 173.2 |
| 78.4 | 83.3 | 132.3 |
| 60.7 | 81.4 | 154.5 |
| 60.9 | 88.2 | 95.1 |
| 55.4 | 82.2 | 198 |
| 82 | 78.1 | 174.5 |
| 64.2 | 118.1 | 117.6 |
| 97.7 | 110.3 | |
| 94.1 | 120.5 | |
| 93.4 | ||
| 63.4 | ||
| 55.2 | ||
| 75.5 | ||
| 81.3 |
Step-by-step procedure to obtain the test statistic using Excel:
- In Sample 1, enter the salary of the group of less than 2 million attendances.
- In Sample 2, enter the salary of the group of 2 up to 3 million attendances.
- In Sample 3, enter the salary of the group of 3 or more million attendances.
- Select the Data tab on the top menu.
- Select Data Analysis and Click on: ANOVA: Single factor and then click on OK.
- In the dialog box, select Input Range.
- Click OK
Output obtained using Excel is represented as follows:
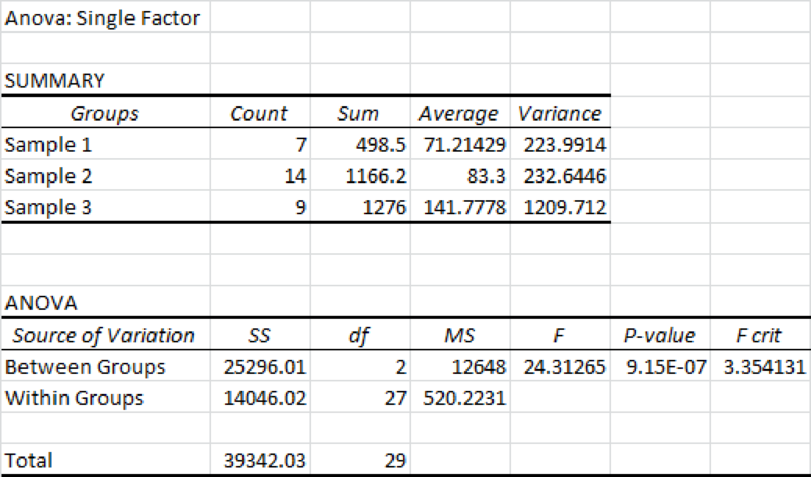
From the above output, the F test statistic value is 24.31 and the p-value is 0.
Conclusion:
The level of significance is 0.05 and the p-value is less than the significance level. Hence, one can reject the null hypothesis at the 0.05 significance level. Thus, the mean salaries are different for each group.
Want to see more full solutions like this?
Chapter 12 Solutions
Statistical Techniques in Business and Economics, 16th Edition


- If a uniform distribution is defined over the interval from 6 to 10, then answer the followings: What is the mean of this uniform distribution? Show that the probability of any value between 6 and 10 is equal to 1.0 Find the probability of a value more than 7. Find the probability of a value between 7 and 9. The closing price of Schnur Sporting Goods Inc. common stock is uniformly distributed between $20 and $30 per share. What is the probability that the stock price will be: More than $27? Less than or equal to $24? The April rainfall in Flagstaff, Arizona, follows a uniform distribution between 0.5 and 3.00 inches. What is the mean amount of rainfall for the month? What is the probability of less than an inch of rain for the month? What is the probability of exactly 1.00 inch of rain? What is the probability of more than 1.50 inches of rain for the month? The best way to solve this problem is begin by a step by step creating a chart. Clearly mark the range, identifying the…arrow_forwardClient 1 Weight before diet (pounds) Weight after diet (pounds) 128 120 2 131 123 3 140 141 4 178 170 5 121 118 6 136 136 7 118 121 8 136 127arrow_forwardClient 1 Weight before diet (pounds) Weight after diet (pounds) 128 120 2 131 123 3 140 141 4 178 170 5 121 118 6 136 136 7 118 121 8 136 127 a) Determine the mean change in patient weight from before to after the diet (after – before). What is the 95% confidence interval of this mean difference?arrow_forward
- In order to find probability, you can use this formula in Microsoft Excel: The best way to understand and solve these problems is by first drawing a bell curve and marking key points such as x, the mean, and the areas of interest. Once marked on the bell curve, figure out what calculations are needed to find the area of interest. =NORM.DIST(x, Mean, Standard Dev., TRUE). When the question mentions “greater than” you may have to subtract your answer from 1. When the question mentions “between (two values)”, you need to do separate calculation for both values and then subtract their results to get the answer. 1. Compute the probability of a value between 44.0 and 55.0. (The question requires finding probability value between 44 and 55. Solve it in 3 steps. In the first step, use the above formula and x = 44, calculate probability value. In the second step repeat the first step with the only difference that x=55. In the third step, subtract the answer of the first part from the…arrow_forwardIf a uniform distribution is defined over the interval from 6 to 10, then answer the followings: What is the mean of this uniform distribution? Show that the probability of any value between 6 and 10 is equal to 1.0 Find the probability of a value more than 7. Find the probability of a value between 7 and 9. The closing price of Schnur Sporting Goods Inc. common stock is uniformly distributed between $20 and $30 per share. What is the probability that the stock price will be: More than $27? Less than or equal to $24? The April rainfall in Flagstaff, Arizona, follows a uniform distribution between 0.5 and 3.00 inches. What is the mean amount of rainfall for the month? What is the probability of less than an inch of rain for the month? What is the probability of exactly 1.00 inch of rain? What is the probability of more than 1.50 inches of rain for the month? The best way to solve this problem is begin by creating a chart. Clearly mark the range, identifying the lower and upper…arrow_forwardProblem 1: The mean hourly pay of an American Airlines flight attendant is normally distributed with a mean of 40 per hour and a standard deviation of 3.00 per hour. What is the probability that the hourly pay of a randomly selected flight attendant is: Between the mean and $45 per hour? More than $45 per hour? Less than $32 per hour? Problem 2: The mean of a normal probability distribution is 400 pounds. The standard deviation is 10 pounds. What is the area between 415 pounds and the mean of 400 pounds? What is the area between the mean and 395 pounds? What is the probability of randomly selecting a value less than 395 pounds? Problem 3: In New York State, the mean salary for high school teachers in 2022 was 81,410 with a standard deviation of 9,500. Only Alaska’s mean salary was higher. Assume New York’s state salaries follow a normal distribution. What percent of New York State high school teachers earn between 70,000 and 75,000? What percent of New York State high school…arrow_forward
- Pls help asaparrow_forwardSolve the following LP problem using the Extreme Point Theorem: Subject to: Maximize Z-6+4y 2+y≤8 2x + y ≤10 2,y20 Solve it using the graphical method. Guidelines for preparation for the teacher's questions: Understand the basics of Linear Programming (LP) 1. Know how to formulate an LP model. 2. Be able to identify decision variables, objective functions, and constraints. Be comfortable with graphical solutions 3. Know how to plot feasible regions and find extreme points. 4. Understand how constraints affect the solution space. Understand the Extreme Point Theorem 5. Know why solutions always occur at extreme points. 6. Be able to explain how optimization changes with different constraints. Think about real-world implications 7. Consider how removing or modifying constraints affects the solution. 8. Be prepared to explain why LP problems are used in business, economics, and operations research.arrow_forwardged the variance for group 1) Different groups of male stalk-eyed flies were raised on different diets: a high nutrient corn diet vs. a low nutrient cotton wool diet. Investigators wanted to see if diet quality influenced eye-stalk length. They obtained the following data: d Diet Sample Mean Eye-stalk Length Variance in Eye-stalk d size, n (mm) Length (mm²) Corn (group 1) 21 2.05 0.0558 Cotton (group 2) 24 1.54 0.0812 =205-1.54-05T a) Construct a 95% confidence interval for the difference in mean eye-stalk length between the two diets (e.g., use group 1 - group 2).arrow_forward
- An article in Business Week discussed the large spread between the federal funds rate and the average credit card rate. The table below is a frequency distribution of the credit card rate charged by the top 100 issuers. Credit Card Rates Credit Card Rate Frequency 18% -23% 19 17% -17.9% 16 16% -16.9% 31 15% -15.9% 26 14% -14.9% Copy Data 8 Step 1 of 2: Calculate the average credit card rate charged by the top 100 issuers based on the frequency distribution. Round your answer to two decimal places.arrow_forwardPlease could you check my answersarrow_forwardLet Y₁, Y2,, Yy be random variables from an Exponential distribution with unknown mean 0. Let Ô be the maximum likelihood estimates for 0. The probability density function of y; is given by P(Yi; 0) = 0, yi≥ 0. The maximum likelihood estimate is given as follows: Select one: = n Σ19 1 Σ19 n-1 Σ19: n² Σ1arrow_forward
 Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL