
PROGRAMMABLE LOGIC CONTROLLERS (LOOSE PA
5th Edition
ISBN: 9781264206216
Author: Petruzella
Publisher: MCG
expand_more
expand_more
format_list_bulleted
Concept explainers
Question
Chapter 12, Problem 1RQ
Program Plan Intro
Sequencers:
- Programmable Logic Controller (PLC) sequencer performs ON or OFF output patterns using sequencer instructions.
- The sequencer output instruction is used for controlling the output devices.
- PLC sequencer instructions are used for controlling machines which provides a stepped sequence of repeatable operations.
- It simplifies the ladder program by allowing the user to use a single or pair of instructions for performing complex operations.
- Various sequencer instructions can be programmed based on the PLC manufacturer.
Drum switch:
- Drum switch is also known as sequencer switch.
- The drum switch includes a series of normally open contact blocks which are operated by pegs situated on a motor-driven drum.
Expert Solution & Answer
Explanation of Solution
Operation of a drum switch:
The operation of a drum switch is described as given below.
- In a drum sequencer, the pegs are situated at specific locations around the circumference of the drum for operating the contact blocks.
- When the drum starts rotating, no pegs will remain open and all the contacts that are arranged in a line with the pegs will remain closed.
- Logic 1 or ON is used to indicate the presence of a peg and logic 0 or OFF is used to indicate the absence of a peg.
The
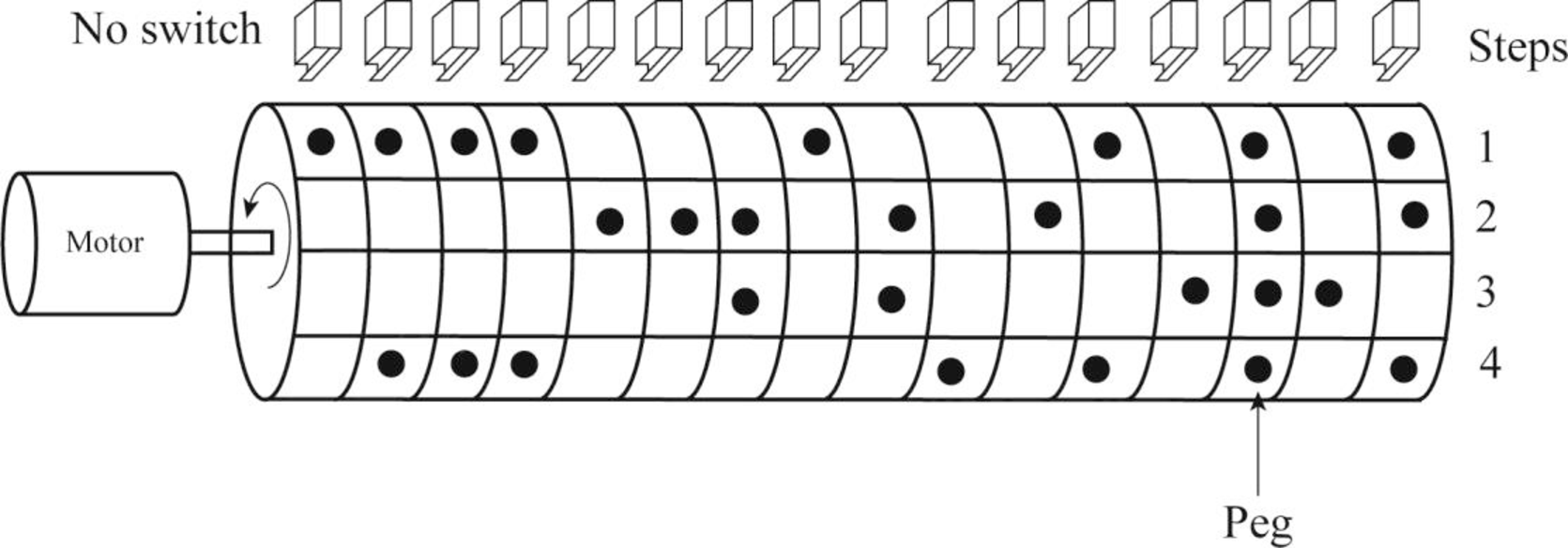
- The ON/OFF operation of 16 discrete outputs is controlled by the drum cylinder.
- The data table given below is used to illustrate the logic state for the first four steps of the drum cylinder.
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 | 0 |
| 0 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
Here, each location where a peg is present is represented by 1 (ON) and the locations where there are no pegs are represented by 0 (OFF).
Want to see more full solutions like this?
Subscribe now to access step-by-step solutions to millions of textbook problems written by subject matter experts!
Students have asked these similar questions
Why I need ?
Here are two diagrams. Make them very explicit, similar to Example Diagram 3 (the Architecture of MSCTNN).
graph LR subgraph Teacher_Model_B [Teacher Model (Pretrained)] Input_Teacher_B[Input C (Complete Data)] --> Teacher_Encoder_B[Transformer Encoder T] Teacher_Encoder_B --> Teacher_Prediction_B[Teacher Prediction y_T] Teacher_Encoder_B --> Teacher_Features_B[Internal Features F_T] end subgraph Student_B_Model [Student Model B (Handles Missing Labels)] Input_Student_B[Input C (Complete Data)] --> Student_B_Encoder[Transformer Encoder E_B] Student_B_Encoder --> Student_B_Prediction[Student B Prediction y_B] end subgraph Knowledge_Distillation_B [Knowledge Distillation (Student B)] Teacher_Prediction_B -- Logits Distillation Loss (L_logits_B) --> Total_Loss_B Teacher_Features_B -- Feature Alignment Loss (L_feature_B) --> Total_Loss_B Partial_Labels_B[Partial Labels y_p] -- Prediction Loss (L_pred_B) --> Total_Loss_B Total_Loss_B -- Backpropagation -->…
Please provide me with the output image of both of them . below are the diagrams code
I have two diagram :
first diagram code
graph LR subgraph Teacher Model (Pretrained) Input_Teacher[Input C (Complete Data)] --> Teacher_Encoder[Transformer Encoder T] Teacher_Encoder --> Teacher_Prediction[Teacher Prediction y_T] Teacher_Encoder --> Teacher_Features[Internal Features F_T] end subgraph Student_A_Model[Student Model A (Handles Missing Values)] Input_Student_A[Input M (Data with Missing Values)] --> Student_A_Encoder[Transformer Encoder E_A] Student_A_Encoder --> Student_A_Prediction[Student A Prediction y_A] Student_A_Encoder --> Student_A_Features[Student A Features F_A] end subgraph Knowledge_Distillation_A [Knowledge Distillation (Student A)] Teacher_Prediction -- Logits Distillation Loss (L_logits_A) --> Total_Loss_A Teacher_Features -- Feature Alignment Loss (L_feature_A) --> Total_Loss_A Ground_Truth_A[Ground Truth y_gt] -- Prediction Loss (L_pred_A)…
Chapter 12 Solutions
PROGRAMMABLE LOGIC CONTROLLERS (LOOSE PA
Knowledge Booster


Learn more about
Need a deep-dive on the concept behind this application? Look no further. Learn more about this topic, computer-science and related others by exploring similar questions and additional content below.Similar questions
- I'm reposting my question again please make sure to avoid any copy paste from the previous answer because those answer did not satisfy or responded to the need that's why I'm asking again The knowledge distillation part is not very clear in the diagram. Please create two new diagrams by separating the two student models: First Diagram (Student A - Missing Values): Clearly illustrate the student training process. Show how knowledge distillation happens between the teacher and Student A. Explain what the teacher teaches Student A (e.g., handling missing values) and how this teaching occurs (e.g., through logits, features, or attention). Second Diagram (Student B - Missing Labels): Similarly, detail the training process for Student B. Clarify how knowledge distillation works between the teacher and Student B. Specify what the teacher teaches Student B (e.g., dealing with missing labels) and how the knowledge is transferred. Since these are two distinct challenges…arrow_forwardThe knowledge distillation part is not very clear in the diagram. Please create two new diagrams by separating the two student models: First Diagram (Student A - Missing Values): Clearly illustrate the student training process. Show how knowledge distillation happens between the teacher and Student A. Explain what the teacher teaches Student A (e.g., handling missing values) and how this teaching occurs (e.g., through logits, features, or attention). Second Diagram (Student B - Missing Labels): Similarly, detail the training process for Student B. Clarify how knowledge distillation works between the teacher and Student B. Specify what the teacher teaches Student B (e.g., dealing with missing labels) and how the knowledge is transferred. Since these are two distinct challenges (missing values vs. missing labels), they should not be combined in the same diagram. Instead, create two separate diagrams for clarity. For reference, I will attach a second image…arrow_forwardNote : please avoid using AI answer the question by carefully reading it and provide a clear and concise solutionHere is a clear background and explanation of the full method, including what each part is doing and why. Background & Motivation Missing values: Some input features (sensor channels) are missing for some samples due to sensor failure or corruption. Missing labels: Not all samples have a ground-truth RUL value. For example, data collected during normal operation is often unlabeled. Most traditional deep learning models require complete data and full labels. But in our case, both are incomplete. If we try to train a model directly, it will either fail to learn properly or discard valuable data. What We Are Doing: Overview We solve this using a Teacher–Student knowledge distillation framework: We train a Teacher model on a clean and complete dataset where both inputs and labels are available. We then use that Teacher to teach two separate Student models: Student A learns…arrow_forward
- Here is a clear background and explanation of the full method, including what each part is doing and why. Background & Motivation Missing values: Some input features (sensor channels) are missing for some samples due to sensor failure or corruption. Missing labels: Not all samples have a ground-truth RUL value. For example, data collected during normal operation is often unlabeled. Most traditional deep learning models require complete data and full labels. But in our case, both are incomplete. If we try to train a model directly, it will either fail to learn properly or discard valuable data. What We Are Doing: Overview We solve this using a Teacher–Student knowledge distillation framework: We train a Teacher model on a clean and complete dataset where both inputs and labels are available. We then use that Teacher to teach two separate Student models: Student A learns from incomplete input (some sensor values missing). Student B learns from incomplete labels (RUL labels missing…arrow_forwardhere is a diagram code : graph LR subgraph Inputs [Inputs] A[Input C (Complete Data)] --> TeacherModel B[Input M (Missing Data)] --> StudentA A --> StudentB end subgraph TeacherModel [Teacher Model (Pretrained)] C[Transformer Encoder T] --> D{Teacher Prediction y_t} C --> E[Internal Features f_t] end subgraph StudentA [Student Model A (Trainable - Handles Missing Input)] F[Transformer Encoder S_A] --> G{Student A Prediction y_s^A} B --> F end subgraph StudentB [Student Model B (Trainable - Handles Missing Labels)] H[Transformer Encoder S_B] --> I{Student B Prediction y_s^B} A --> H end subgraph GroundTruth [Ground Truth RUL (Partial Labels)] J[RUL Labels] end subgraph KnowledgeDistillationA [Knowledge Distillation Block for Student A] K[Prediction Distillation Loss (y_s^A vs y_t)] L[Feature Alignment Loss (f_s^A vs f_t)] D -- Prediction Guidance --> K E -- Feature Guidance --> L G --> K F --> L J -- Supervised Guidance (if available) --> G K…arrow_forwarddetails explanation and background We solve this using a Teacher–Student knowledge distillation framework: We train a Teacher model on a clean and complete dataset where both inputs and labels are available. We then use that Teacher to teach two separate Student models: Student A learns from incomplete input (some sensor values missing). Student B learns from incomplete labels (RUL labels missing for some samples). We use knowledge distillation to guide both students, even when labels are missing. Why We Use Two Students Student A handles Missing Input Features: It receives input with some features masked out. Since it cannot see the full input, we help it by transferring internal features (feature distillation) and predictions from the teacher. Student B handles Missing RUL Labels: It receives full input but does not always have a ground-truth RUL label. We guide it using the predictions of the teacher model (prediction distillation). Using two students allows each to specialize in…arrow_forward
- We are doing a custom JSTL custom tag to make display page to access a tag handler. Write two custom tags: 1) A single tag which prints a number (from 0-99) as words. Ex: <abc:numAsWords val="32"/> --> produces: thirty-two 2) A paired tag which puts the body in a DIV with our team colors. Ex: <abc:teamColors school="gophers" reverse="true"> <p>Big game today</p> <p>Bring your lucky hat</p> <-- these will be green text on blue background </abc:teamColors> Details: The attribute for numAsWords will be just val, from 0 to 99 - spelling, etc... isn't important here. Print "twenty-six" or "Twenty six" ... . Attributes for teamColors are: school, a "required" string, and reversed, a non-required boolean. - pick any four schools. I picked gophers, cyclones, hawkeyes and cornhuskers - each school has two colors. Pick whatever seems best. For oine I picked "cyclones" and red text on a gold body - if…arrow_forwardI want a database on MySQL to analyze blood disease analyses with a selection of all its commands, with an ER drawing, and a complete chart for normalization. I want them completely.arrow_forwardAssignment Instructions: You are tasked with developing a program to use city data from an online database and generate a city details report. 1) Create a new Project in Eclipse called "HW7". 2) Create a class "City.java" in the project and implement the UML diagram shown below and add comments to your program. 3) The logic for the method "getCityCategory" of City Class is below: a. If the population of a city is greater than 10000000, then the method returns "MEGA" b. If the population of a city is greater than 1000000 and less than 10000000, then the method returns "LARGE" c. If the population of a city is greater than 100000 and less than 1000000, then the method returns "MEDIUM" d. If the population of a city is below 100000, then the method returns "SMALL" 4) You should create another new Java program inside the project. Name the program as "xxxx_program.java”, where xxxx is your Kean username. 3) Implement the following methods inside the xxxx_program program The main method…arrow_forward
- CPS 2231 - Computer Programming – Spring 2025 City Report Application - Due Date: Concepts: Classes and Objects, Reading from a file and generating report Point value: 40 points. The purpose of this project is to give students exposure to object-oriented design and programming using classes in a realistic application that involves arrays of objects and generating reports. Assignment Instructions: You are tasked with developing a program to use city data from an online database and generate a city details report. 1) Create a new Project in Eclipse called "HW7”. 2) Create a class "City.java" in the project and implement the UML diagram shown below and add comments to your program. 3) The logic for the method "getCityCategory" of City Class is below: a. If the population of a city is greater than 10000000, then the method returns "MEGA" b. If the population of a city is greater than 1000000 and less than 10000000, then the method returns "LARGE" c. If the population of a city is greater…arrow_forwardPlease calculate the average best-case IPC attainable on this code with a 2-wide, in-order, superscalar machine: ADD X1, X2, X3 SUB X3, X1, 0x100 ORR X9, X10, X11 ADD X11, X3, X2 SUB X9, X1, X3 ADD X1, X2, X3 AND X3, X1, X9 ORR X1, X11, X9 SUB X13, X14, X15 ADD X16, X13, X14arrow_forwardOutline the overall steps for configuring and securing Linux servers Consider and describe how a mixed Operating System environment will affect what you have to do to protect the company assets Describe at least three technologies that will help to protect CIA of data on Linux systemsarrow_forward
arrow_back_ios
SEE MORE QUESTIONS
arrow_forward_ios
Recommended textbooks for you
 A+ Guide to Hardware (Standalone Book) (MindTap C...Computer ScienceISBN:9781305266452Author:Jean AndrewsPublisher:Cengage Learning
A+ Guide to Hardware (Standalone Book) (MindTap C...Computer ScienceISBN:9781305266452Author:Jean AndrewsPublisher:Cengage Learning Enhanced Discovering Computers 2017 (Shelly Cashm...Computer ScienceISBN:9781305657458Author:Misty E. Vermaat, Susan L. Sebok, Steven M. Freund, Mark Frydenberg, Jennifer T. CampbellPublisher:Cengage Learning
Enhanced Discovering Computers 2017 (Shelly Cashm...Computer ScienceISBN:9781305657458Author:Misty E. Vermaat, Susan L. Sebok, Steven M. Freund, Mark Frydenberg, Jennifer T. CampbellPublisher:Cengage Learning Systems ArchitectureComputer ScienceISBN:9781305080195Author:Stephen D. BurdPublisher:Cengage Learning
Systems ArchitectureComputer ScienceISBN:9781305080195Author:Stephen D. BurdPublisher:Cengage Learning
 CompTIA Linux+ Guide to Linux Certification (Mind...Computer ScienceISBN:9781305107168Author:Jason EckertPublisher:Cengage Learning
CompTIA Linux+ Guide to Linux Certification (Mind...Computer ScienceISBN:9781305107168Author:Jason EckertPublisher:Cengage Learning A+ Guide To It Technical SupportComputer ScienceISBN:9780357108291Author:ANDREWS, Jean.Publisher:Cengage,
A+ Guide To It Technical SupportComputer ScienceISBN:9780357108291Author:ANDREWS, Jean.Publisher:Cengage,
A+ Guide to Hardware (Standalone Book) (MindTap C...
Computer Science
ISBN:9781305266452
Author:Jean Andrews
Publisher:Cengage Learning
Enhanced Discovering Computers 2017 (Shelly Cashm...
Computer Science
ISBN:9781305657458
Author:Misty E. Vermaat, Susan L. Sebok, Steven M. Freund, Mark Frydenberg, Jennifer T. Campbell
Publisher:Cengage Learning
Systems Architecture
Computer Science
ISBN:9781305080195
Author:Stephen D. Burd
Publisher:Cengage Learning
CompTIA Linux+ Guide to Linux Certification (Mind...
Computer Science
ISBN:9781305107168
Author:Jason Eckert
Publisher:Cengage Learning
A+ Guide To It Technical Support
Computer Science
ISBN:9780357108291
Author:ANDREWS, Jean.
Publisher:Cengage,