
Concept explainers
Videos
(a)
The
(a)
Answer to Problem 23P
Solution: The provided values, that is,
Explanation of Solution
Given: The provided table consists of values of x and y, where x represents the average annual hours spent by a person in traffic delay, y represents the average annual gallons of fuel wasted per person due to traffic delay. The data consists of 8 data pairs, thus n is 8.
Calculation: Follow the steps given below in MS Excel to obtain the scatter plot of the data.
Step 1: Enter the data into an MS Excel sheet. The screenshot is given below.
Step 2: Select the data and click on ‘Insert’. Go to charts and select the chart type ‘Scatter’.
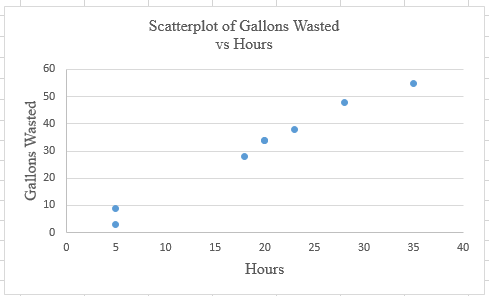
Step 3: Select the first plot and then click ‘add chart element’ provided in the left corner of the menu bar. Insert the ‘Axis titles’ and ‘Chart title’. The scatter plot for the provided data is shown below:
To calculate
| 28 | 48 | 784 | 2304 | 1344 |
| 5 | 3 | 25 | 9 | 15 |
| 20 | 34 | 400 | 1156 | 680 |
| 35 | 55 | 1225 | 3025 | 1925 |
| 20 | 34 | 400 | 1156 | 680 |
| 23 | 38 | 529 | 1444 | 874 |
| 18 | 28 | 324 | 784 | 504 |
| 5 | 9 | 25 | 81 | 45 |
The provided values,
Now, the value of
Substituting the values in the above formula. Thus:
Therefore, the correlation coefficient is 0.991.
(b)
The averages
(b)
Answer to Problem 23P
Solution: The values for data set 1 are
The values for data set 2 are
Explanation of Solution
Given: The provided table consists of values of x and y, where x represents the average annual hours spent by a person in traffic delay, y represents the average annual gallons of fuel wasted per person due to traffic delay.
The second table consists of x and y values where, x represent the annual hours lost by a person spent in traffic delay, y represents the annual gallons of fuel wasted by that person in traffic delay.
The data sets consist of 8 data pairs, thus n is 8 for both the data sets.
The provided values of data set 1 are,
The provided values of data set 2 are,
Calculation:
The value of
The value of
The standard deviation of x for data set 1 can be calculated as,
The standard deviation of
The value of
The value of
The standard deviation of
The standard deviation of
For the second data set, that is, for the variables based on single individuals, the standard deviations
The values
(c)
The scatter plot, whether the provided values of
(c)
Answer to Problem 23P
Solution: The provided values, that is,
Explanation of Solution
The provided table consists of values of x and y, where x represents the average annual hours spent by a person in traffic delay, y represents the average annual gallons of fuel wasted per person due to traffic delay.
The data sets consist of 8 data pairs, thus n is 8.
Calculation: Follow the steps given below in MS Excel to obtain the scatter plot of the data.
Step 1: Enter the data into an MS Excel sheet. The screenshot is given below.
Step 2: Select the data and click on ‘Insert’. Go to charts and select the chart type ‘Scatter’.
Step 3: Select the first plot and then click ‘add chart element’ provided in the left corner of the menu bar. Insert the ‘Axis titles’ and ‘Chart title’. The scatter plot for the provided data is shown below:
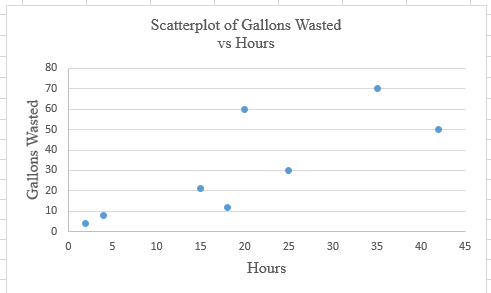
Calculation: The calculation for
| 20 | 60 | 400 | 3600 | 1200 |
| 4 | 8 | 16 | 64 | 32 |
| 18 | 12 | 324 | 144 | 216 |
| 42 | 50 | 1764 | 2500 | 2100 |
| 15 | 21 | 225 | 441 | 315 |
| 25 | 30 | 625 | 900 | 750 |
| 2 | 4 | 4 | 16 | 8 |
| 35 | 70 | 1225 | 4900 | 2450 |
The provided values,
Now, the value of
Substituting the values in the above formula. Thus:
Therefore, the correlation coefficient is 0.794.
(d)
Comparison between the values of r that are calculated in part (a) and part (c), whether the data for average have a higher correlation coefficient than the data for individual measurement or not, and the reason for it.
(d)
Answer to Problem 23P
Solution: Yes, the data for average has a higher correlation coefficient than the data for individual measurement because, according to the central limit theorem, the standard deviation of averages will be smaller than the standard deviation of individual values.
Explanation of Solution
Given: The values of correlation coefficient from part (a) and part (b) are 0.991 and 0.794, respectively.
It can be seen that
According to the central limit theorem, the standard deviation is smaller for the
Want to see more full solutions like this?
Chapter 4 Solutions
Bundle: Understanding Basic Statistics, Loose-leaf Version, 7th + WebAssign Printed Access Card for Brase/Brase's Understanding Basic Statistics, ... for Peck's Statistics: Learning from Data


- Binomial Prob. Question: A new teaching method claims to improve student engagement. A survey reveals that 60% of students find this method engaging. If 15 students are randomly selected, what is the probability that: a) Exactly 9 students find the method engaging?b) At least 7 students find the method engaging? (2 points = 1 x 2 answers) Provide answers in the yellow cellsarrow_forwardIn a survey of 2273 adults, 739 say they believe in UFOS. Construct a 95% confidence interval for the population proportion of adults who believe in UFOs. A 95% confidence interval for the population proportion is ( ☐, ☐ ). (Round to three decimal places as needed.)arrow_forwardFind the minimum sample size n needed to estimate μ for the given values of c, σ, and E. C=0.98, σ 6.7, and E = 2 Assume that a preliminary sample has at least 30 members. n = (Round up to the nearest whole number.)arrow_forward
- In a survey of 2193 adults in a recent year, 1233 say they have made a New Year's resolution. Construct 90% and 95% confidence intervals for the population proportion. Interpret the results and compare the widths of the confidence intervals. The 90% confidence interval for the population proportion p is (Round to three decimal places as needed.) J.D) .arrow_forwardLet p be the population proportion for the following condition. Find the point estimates for p and q. In a survey of 1143 adults from country A, 317 said that they were not confident that the food they eat in country A is safe. The point estimate for p, p, is (Round to three decimal places as needed.) ...arrow_forward(c) Because logistic regression predicts probabilities of outcomes, observations used to build a logistic regression model need not be independent. A. false: all observations must be independent B. true C. false: only observations with the same outcome need to be independent I ANSWERED: A. false: all observations must be independent. (This was marked wrong but I have no idea why. Isn't this a basic assumption of logistic regression)arrow_forward
- Business discussarrow_forwardSpam filters are built on principles similar to those used in logistic regression. We fit a probability that each message is spam or not spam. We have several variables for each email. Here are a few: to_multiple=1 if there are multiple recipients, winner=1 if the word 'winner' appears in the subject line, format=1 if the email is poorly formatted, re_subj=1 if "re" appears in the subject line. A logistic model was fit to a dataset with the following output: Estimate SE Z Pr(>|Z|) (Intercept) -0.8161 0.086 -9.4895 0 to_multiple -2.5651 0.3052 -8.4047 0 winner 1.5801 0.3156 5.0067 0 format -0.1528 0.1136 -1.3451 0.1786 re_subj -2.8401 0.363 -7.824 0 (a) Write down the model using the coefficients from the model fit.log_odds(spam) = -0.8161 + -2.5651 + to_multiple + 1.5801 winner + -0.1528 format + -2.8401 re_subj(b) Suppose we have an observation where to_multiple=0, winner=1, format=0, and re_subj=0. What is the predicted probability that this message is spam?…arrow_forwardConsider an event X comprised of three outcomes whose probabilities are 9/18, 1/18,and 6/18. Compute the probability of the complement of the event. Question content area bottom Part 1 A.1/2 B.2/18 C.16/18 D.16/3arrow_forward
- John and Mike were offered mints. What is the probability that at least John or Mike would respond favorably? (Hint: Use the classical definition.) Question content area bottom Part 1 A.1/2 B.3/4 C.1/8 D.3/8arrow_forwardThe details of the clock sales at a supermarket for the past 6 weeks are shown in the table below. The time series appears to be relatively stable, without trend, seasonal, or cyclical effects. The simple moving average value of k is set at 2. What is the simple moving average root mean square error? Round to two decimal places. Week Units sold 1 88 2 44 3 54 4 65 5 72 6 85 Question content area bottom Part 1 A. 207.13 B. 20.12 C. 14.39 D. 0.21arrow_forwardThe details of the clock sales at a supermarket for the past 6 weeks are shown in the table below. The time series appears to be relatively stable, without trend, seasonal, or cyclical effects. The simple moving average value of k is set at 2. If the smoothing constant is assumed to be 0.7, and setting F1 and F2=A1, what is the exponential smoothing sales forecast for week 7? Round to the nearest whole number. Week Units sold 1 88 2 44 3 54 4 65 5 72 6 85 Question content area bottom Part 1 A. 80 clocks B. 60 clocks C. 70 clocks D. 50 clocksarrow_forward
 Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt