
Concept explainers
Videos
a.
Find the population standard deviation for the prices in May.
a.
Answer to Problem 6RE
- The population standard deviation for the prices in May is 0.791.
Explanation of Solution
Calculation:
The closing prices of google stock in May and June are given.
Standard deviation:
Let
Population standard deviation:
Finding mean:
Software procedure:
Step-by-step procedure to find mean using the MINITAB software:
- Choose Stat > Basic Statistics > Display
Descriptive Statistics . - In Variables enter the columns May.
- Choose option statistics, and select N total, Mean.
- Click OK.
Output using the MINITAB software is given below:
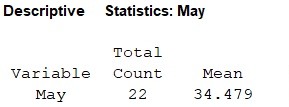
- From the MINITAB output the mean is 34.479.
The deviation, deviation’s squares are calculated below:
| x | ||
| 34.54 | 0.061 | 0.004 |
| 33.27 | –1.209 | 1.462 |
| 34.4 | –0.079 | 0.006 |
| 35.67 | 1.191 | 1.418 |
| 33.16 | –1.319 | 1.74 |
| 34.62 | 0.141 | 0.02 |
| 33.49 | –0.989 | 0.978 |
| 34.72 | 0.241 | 0.058 |
| 34.96 | 0.481 | 0.231 |
| 32.72 | –1.759 | 3.094 |
| 34.35 | –0.129 | 0.017 |
| 34.59 | 0.111 | 0.012 |
| 35 | 0.521 | 0.271 |
| 34.78 | 0.301 | 0.091 |
| 33.67 | –0.809 | 0.654 |
| 34.98 | 0.501 | 0.251 |
| 34.84 | 0.361 | 0.13 |
| 34.99 | 0.511 | 0.261 |
| 33.72 | –0.759 | 0.576 |
| 35 | 0.521 | 0.271 |
| 35.47 | 0.991 | 0.982 |
| 35.59 | 1.111 | 1.234 |
| Total |
Substituting
- Hence, the population standard deviation for the prices in May is 0.791.
b.
Find the population standard deviation for the prices in June.
b.
Answer to Problem 6RE
- The population standard deviation for the prices in June is 0.814.
- .
Explanation of Solution
Calculation:
Population standard deviation:
Finding mean:
Software procedure:
Step-by-step procedure to find mean using the MINITAB software:
- Choose Stat > Basic Statistics > Display Descriptive Statistics.
- In Variables enter the columns June.
- Choose option statistics, and select N total, Mean.
- Click OK.
Output using the MINITAB software is given below:
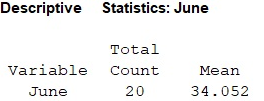
- From the MINITAB output the mean is 34.052.
The deviation, deviation’s squares are calculated below:
| x | ||
| 34.9 | 0.848 | 0.719 |
| 34.15 | 0.098 | 0.01 |
| 34.08 | 0.028 | 8E–04 |
| 32.66 | –1.392 | 1.938 |
| 35.03 | 0.978 | 0.956 |
| 34.61 | 0.558 | 0.311 |
| 33.85 | –0.202 | 0.041 |
| 32.99 | –1.062 | 1.128 |
| 34.88 | 0.828 | 0.686 |
| 34.85 | 0.798 | 0.637 |
| 33.53 | –0.522 | 0.272 |
| 33.31 | –0.742 | 0.551 |
| 35.02 | 0.968 | 0.937 |
| 35.08 | 1.028 | 1.057 |
| 33.03 | –1.022 | 1.044 |
| 33.75 | –0.302 | 0.091 |
| 34.27 | 0.218 | 0.048 |
| 34.87 | 0.818 | 0.669 |
| 32.69 | –1.362 | 1.855 |
| 33.49 | –0.562 | 0.316 |
| Total |
Substituting
- Hence, the population standard deviation for the prices in June is 0.814.
c.
Find the month when the price of Google stock more volatile.
c.
Answer to Problem 6RE
- The spreads for the prices in June has increased in 2013.
Explanation of Solution
- The financial analysts use the term “volatility” for referring the price variation of assets as stocks.
- From part (a), the population standard deviation for the prices in May is 0.791.
- From part (b), the population standard deviation for the prices in June is 0.814.
- The standard deviation for the prices in June is slightly more than the population standard deviation for the prices in May.
- Thus, it can be concluded that the spreads for the prices in June is more volatile than May.
Want to see more full solutions like this?
Chapter 3 Solutions
ALEKS 360 ESSENT. STAT ACCESS CARD


- Questions An insurance company's cumulative incurred claims for the last 5 accident years are given in the following table: Development Year Accident Year 0 2018 1 2 3 4 245 267 274 289 292 2019 255 276 288 294 2020 265 283 292 2021 263 278 2022 271 It can be assumed that claims are fully run off after 4 years. The premiums received for each year are: Accident Year Premium 2018 306 2019 312 2020 318 2021 326 2022 330 You do not need to make any allowance for inflation. 1. (a) Calculate the reserve at the end of 2022 using the basic chain ladder method. (b) Calculate the reserve at the end of 2022 using the Bornhuetter-Ferguson method. 2. Comment on the differences in the reserves produced by the methods in Part 1.arrow_forwardA population that is uniformly distributed between a=0and b=10 is given in sample sizes 50( ), 100( ), 250( ), and 500( ). Find the sample mean and the sample standard deviations for the given data. Compare your results to the average of means for a sample of size 10, and use the empirical rules to analyze the sampling error. For each sample, also find the standard error of the mean using formula given below. Standard Error of the Mean =sigma/Root Complete the following table with the results from the sampling experiment. (Round to four decimal places as needed.) Sample Size Average of 8 Sample Means Standard Deviation of 8 Sample Means Standard Error 50 100 250 500arrow_forwardA survey of 250250 young professionals found that two dash thirdstwo-thirds of them use their cell phones primarily for e-mail. Can you conclude statistically that the population proportion who use cell phones primarily for e-mail is less than 0.720.72? Use a 95% confidence interval. Question content area bottom Part 1 The 95% confidence interval is left bracket nothing comma nothing right bracket0.60820.6082, 0.72510.7251. As 0.720.72 is within the limits of the confidence interval, we cannot conclude that the population proportion is less than 0.720.72. (Use ascending order. Round to four decimal places as needed.)arrow_forward
- I need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forwardA survey of 250 young professionals found that two-thirds of them use their cell phones primarily for e-mail. Can you conclude statistically that the population proportion who use cell phones primarily for e-mail is less than 0.72? Use a 95% confidence interval. Question content area bottom Part 1 The 95% confidence interval is [ ], [ ] As 0.72 is ▼ above the upper limit within the limits below the lower limit of the confidence interval, we ▼ can cannot conclude that the population proportion is less than 0.72. (Use ascending order. Round to four decimal places as needed.)arrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forward
- I need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forwardI need help with this problem and an explanation of the solution for the image described below. (Statistics: Engineering Probabilities)arrow_forwardQuestions An insurance company's cumulative incurred claims for the last 5 accident years are given in the following table: Development Year Accident Year 0 2018 1 2 3 4 245 267 274 289 292 2019 255 276 288 294 2020 265 283 292 2021 263 278 2022 271 It can be assumed that claims are fully run off after 4 years. The premiums received for each year are: Accident Year Premium 2018 306 2019 312 2020 318 2021 326 2022 330 You do not need to make any allowance for inflation. 1. (a) Calculate the reserve at the end of 2022 using the basic chain ladder method. (b) Calculate the reserve at the end of 2022 using the Bornhuetter-Ferguson method. 2. Comment on the differences in the reserves produced by the methods in Part 1.arrow_forward
- Questions An insurance company's cumulative incurred claims for the last 5 accident years are given in the following table: Development Year Accident Year 0 2018 1 2 3 4 245 267 274 289 292 2019 255 276 288 294 2020 265 283 292 2021 263 278 2022 271 It can be assumed that claims are fully run off after 4 years. The premiums received for each year are: Accident Year Premium 2018 306 2019 312 2020 318 2021 326 2022 330 You do not need to make any allowance for inflation. 1. (a) Calculate the reserve at the end of 2022 using the basic chain ladder method. (b) Calculate the reserve at the end of 2022 using the Bornhuetter-Ferguson method. 2. Comment on the differences in the reserves produced by the methods in Part 1.arrow_forwardFrom a sample of 26 graduate students, the mean number of months of work experience prior to entering an MBA program was 34.67. The national standard deviation is known to be18 months. What is a 90% confidence interval for the population mean? Question content area bottom Part 1 A 9090% confidence interval for the population mean is left bracket nothing comma nothing right bracketenter your response here,enter your response here. (Use ascending order. Round to two decimal places as needed.)arrow_forwardA test consists of 10 questions made of 5 answers with only one correct answer. To pass the test, a student must answer at least 8 questions correctly. (a) If a student guesses on each question, what is the probability that the student passes the test? (b) Find the mean and standard deviation of the number of correct answers. (c) Is it unusual for a student to pass the test by guessing? Explain.arrow_forward
 Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL