
Concept explainers
Videos
Decimal Data: Batting Averages The following data represent baseball batting averages for a random sample of National League players neat the end of the baseball season. the data are from the baseball statistics section of the Denver Post.
| 0.194 | 0.258 | 0.190 | 0.291 | 0.158 | 0.295 | 0.261 | 0.250 | 0.181 |
| 0.125 | 0.107 | 0.260 | 0.309 | 0.309 | 0.276 | 0.287 | 0.317 | 0.252 |
| 0.215 | 0.250 | 0.246 | 0.260 | 0.265 | 0.182 | 0.113 | 0.200 |
(a) Multiply each data value by 1000 to “clear” the decimals.
(b) Use the standard procedares of this section to make a frequency table and histogram with your whole-number data. Use five classes.
(c) Divide class limits, class boundaries, and class midpoints by 1000 to get back to your original dat.
(a)
To find: The decimal data that are multiply with 1000 for each value in the data..
Answer to Problem 22P
Solution: The data multiply with 1000 for each value in the data is as follows:
| Data | Data*100 | Data | Data*100 |
| 0.194 | 194 | 0.309 | 309 |
| 0.258 | 258 | 0.276 | 276 |
| 0.19 | 190 | 0.287 | 287 |
| 0.291 | 291 | 0.317 | 317 |
| 0.158 | 158 | 0.252 | 252 |
| 0.295 | 295 | 0.215 | 215 |
| 0.261 | 261 | 0.25 | 250 |
| 0.25 | 250 | 0.246 | 246 |
| 0.181 | 181 | 0.26 | 260 |
| 0.125 | 125 | 0.265 | 265 |
| 0.107 | 107 | 0.182 | 182 |
| 0.26 | 260 | 0.113 | 113 |
| 0.309 | 309 | 0.2 | 200 |
Explanation of Solution
Calculation: The data represent baseball batting averages for a random sample of National League players near the end of the baseball season and there are 26 values in the data set. To find the whole number data by multiplying 1000 is obtained as follows:
| Data | Data*100 | Data | Data*100 |
| 0.194 | 0.309 | 309 | |
| 0.258 | 0.276 | 276 | |
| 0.19 | 0.287 | 287 | |
| 0.291 | 291 | 0.317 | 317 |
| 0.158 | 158 | 0.252 | 252 |
| 0.295 | 295 | 0.215 | 215 |
| 0.261 | 261 | 0.25 | 250 |
| 0.25 | 250 | 0.246 | 246 |
| 0.181 | 181 | 0.26 | 260 |
| 0.125 | 125 | 0.265 | 265 |
| 0.107 | 107 | 0.182 | 182 |
| 0.26 | 260 | 0.113 | 113 |
| 0.309 | 309 | 0.2 | 200 |
Interpretation: Hence, the data multiply with 1000 is as follows:
| Data | Data*100 | Data | Data*100 |
| 0.194 | 194 | 0.309 | 309 |
| 0.258 | 258 | 0.276 | 276 |
| 0.19 | 190 | 0.287 | 287 |
| 0.291 | 291 | 0.317 | 317 |
| 0.158 | 158 | 0.252 | 252 |
| 0.295 | 295 | 0.215 | 215 |
| 0.261 | 261 | 0.25 | 250 |
| 0.25 | 250 | 0.246 | 246 |
| 0.181 | 181 | 0.26 | 260 |
| 0.125 | 125 | 0.265 | 265 |
| 0.107 | 107 | 0.182 | 182 |
| 0.26 | 260 | 0.113 | 113 |
| 0.309 | 309 | 0.2 | 200 |
(b)
To find: The standard frequency table for the data set..
Answer to Problem 22P
Solution: The complete frequency table is as:
| Class limits | Class boundaries | Midpoints | Freq | Relative freq | Cumulative freq |
| 46-85 | 45.5-85.5 | 65.5 | 4 | 0.12 | 4 |
| 86-125 | 85.5-125.5 | 105.5 | 5 | 0.16 | 9 |
| 126-165 | 125.5-165.5 | 145.5 | 10 | 0.31 | 19 |
| 166-205 | 165.5-205.5 | 185.5 | 5 | 0.16 | 24 |
| 206-245 | 205.5-245.5 | 225.5 | 5 | 0.16 | 29 |
| 246-285 | 245.5-285.5 | 265.5 | 3 | 0.09 | 32 |
Explanation of Solution
Calculation: To find the class width for the whole data of 26 values, it is observed that largest value of the data set is 317 and the smallest value is 107 in the data. Using 5 classes, the class width calculated in the following way:
The value is round up to the nearest whole number. Hence, the class width of the data set is 43. The class width for the data is 43 and the lowest data value (107) will be the lower class limit of the first class. Because the class width is 43, it must add 43 to the lowest class limit in the first class to find the lowest class limit in the second class. There are 5 desired classes. Hence, the class limits are 107–149, 150–192, 193–235, 236–278, and 279–321. Now, to find the class boundaries subtract 0.5 from lower limit of every class and add 0.5 to the upper limit of the every class interval. Hence, the class boundaries are 106.5–149.5, 149.5–192.5, 192.5–235.5, 235.5-278.5, and 278.5-321.5.
Next to find the midpoint of the class is calculated by using formula,
Midpoint of first class is calculated as:
The frequencies for respective classes are 3, 4, 3, 10, and 6.
Relative frequency is calculated by using the formula
The frequency for first class is 3 and total frequencies are 26 so the relative frequency is
The calculated frequency table is as follows:
| Class limits | Class boundaries | Midpoints | freq | relative freq |
| 107-149 | 106.5-149.5 | 128 | 3 | 0.12 |
| 150-192 | 149.5-192.5 | 171 | 4 | 0.15 |
| 193-235 | 192.5-235.5 | 214 | 3 | 0.12 |
| 236-278 | 235.5-278.5 | 257 | 10 | 0.38 |
| 279-321 | 278.5-321.5 | 300 | 6 | 0.23 |
Graph: To construct the histogram by using the MINITAB, the steps are as follows:
Step 1: Enter the class boundaries in C1 and frequency in C2.
Step 2: Go to Graph > Histogram > Simple.
Step 3: Enter C1 in Graph variable then go to Data options > Frequency > C2.
Step 4: Click on OK.
The obtained histogram is
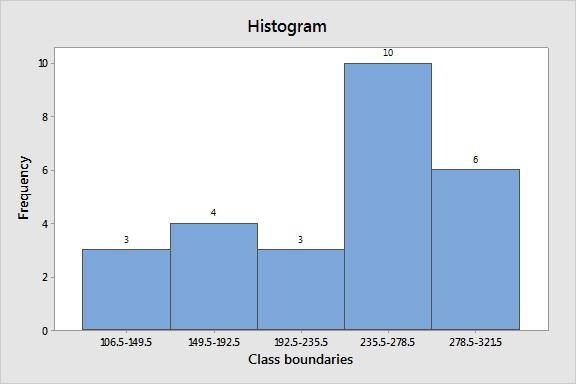
Interpretation: Hence, the complete frequency table is as follows:
| Class limits | Class boundaries | Midpoints | Freq | Relative freq |
| 107-149 | 106.5-149.5 | 128 | 3 | 0.12 |
| 150-192 | 149.5-192.5 | 171 | 4 | 0.15 |
| 193-235 | 192.5-235.5 | 214 | 3 | 0.12 |
| 236-278 | 235.5-278.5 | 257 | 10 | 0.38 |
| 279-321 | 278.5-321.5 | 300 | 6 | 0.23 |
(c)
To find: The class limits, class boundaries, and midpoints in the frequency table by dividing 1000..
Answer to Problem 22P
Solution: The frequency table of original data is as follows:
| Class limits | Class boundaries | Midpoints | |
| 0.107-0.149 | 0.1065-0.1495 | 0.128 | |
| 0.149-0.192 | 0.1495-0.1925 | 0.171 | |
| 0.193-0.235 | 0.1925-0.2355 | 0.214 | |
| 0.236-0.278 | 0.2355-0.2785 | 0.257 | |
| 0.279-0.321 | 0.2785-0.3215 | 0.3 | |
Explanation of Solution
Calculation: The frequency table for whole number is obtained in above part. It is the data that multiply each value by 1000 to ‘clear’ decimals from the data. The frequency table for whole number is as follows:
| Class limits | Class boundaries | Midpoints | Freq | Relative freq |
| 107–149 | 106.5–149.5 | 128 | 3 | 0.12 |
| 150–192 | 149.5–192.5 | 171 | 4 | 0.15 |
| 193–235 | 192.5–235.5 | 214 | 3 | 0.12 |
| 236–278 | 235.5–278.5 | 257 | 10 | 0.38 |
| 279–321 | 278.5–321.5 | 300 | 6 | 0.23 |
To find the decimal or original data, divide the class limits, class boundaries, and midpoints by 1000. The calculation as follows:
| Class limits | Class boundaries | Midpoints | |
| 0.107–0.149 | 0.1065–0.1495 | 0.128 | |
| 0.149–0.192 | 0.1495–0.1925 | 0.171 | |
| 0.193–0.235 | 0.1925–0.2355 | 0.214 | |
| 0.236–0.278 | 0.2355–0.2785 | 0.257 | |
| 0.279–0.321 | 0.2785–0.3215 | 0.3 | |
Interpretation: Hence, the data divide by 1000 is as follows:
| Class limits | Class boundaries | Midpoints | |
| 0.107–0.149 | 0.1065–0.1495 | 0.128 | |
| 0.149–0.192 | 0.1495–0.1925 | 0.171 | |
| 0.193–0.235 | 0.1925–0.2355 | 0.214 | |
| 0.236–0.278 | 0.2355–0.2785 | 0.257 | |
| 0.279–0.321 | 0.2785–0.3215 | 0.300 | |
Want to see more full solutions like this?
Chapter 2 Solutions
EBK UNDERSTANDING BASIC STATISTICS


- Question: A company launches two different marketing campaigns to promote the same product in two different regions. After one month, the company collects the sales data (in units sold) from both regions to compare the effectiveness of the campaigns. The company wants to determine whether there is a significant difference in the mean sales between the two regions. Perform a two sample T-test You can provide your answer by inserting a text box and the answer must include: Null hypothesis, Alternative hypothesis, Show answer (output table/summary table), and Conclusion based on the P value. (2 points = 0.5 x 4 Answers) Each of these is worth 0.5 points. However, showing the calculation is must. If calculation is missing, the whole answer won't get any credit.arrow_forwardBinomial Prob. Question: A new teaching method claims to improve student engagement. A survey reveals that 60% of students find this method engaging. If 15 students are randomly selected, what is the probability that: a) Exactly 9 students find the method engaging?b) At least 7 students find the method engaging? (2 points = 1 x 2 answers) Provide answers in the yellow cellsarrow_forwardIn a survey of 2273 adults, 739 say they believe in UFOS. Construct a 95% confidence interval for the population proportion of adults who believe in UFOs. A 95% confidence interval for the population proportion is ( ☐, ☐ ). (Round to three decimal places as needed.)arrow_forward
- Find the minimum sample size n needed to estimate μ for the given values of c, σ, and E. C=0.98, σ 6.7, and E = 2 Assume that a preliminary sample has at least 30 members. n = (Round up to the nearest whole number.)arrow_forwardIn a survey of 2193 adults in a recent year, 1233 say they have made a New Year's resolution. Construct 90% and 95% confidence intervals for the population proportion. Interpret the results and compare the widths of the confidence intervals. The 90% confidence interval for the population proportion p is (Round to three decimal places as needed.) J.D) .arrow_forwardLet p be the population proportion for the following condition. Find the point estimates for p and q. In a survey of 1143 adults from country A, 317 said that they were not confident that the food they eat in country A is safe. The point estimate for p, p, is (Round to three decimal places as needed.) ...arrow_forward
- (c) Because logistic regression predicts probabilities of outcomes, observations used to build a logistic regression model need not be independent. A. false: all observations must be independent B. true C. false: only observations with the same outcome need to be independent I ANSWERED: A. false: all observations must be independent. (This was marked wrong but I have no idea why. Isn't this a basic assumption of logistic regression)arrow_forwardBusiness discussarrow_forwardSpam filters are built on principles similar to those used in logistic regression. We fit a probability that each message is spam or not spam. We have several variables for each email. Here are a few: to_multiple=1 if there are multiple recipients, winner=1 if the word 'winner' appears in the subject line, format=1 if the email is poorly formatted, re_subj=1 if "re" appears in the subject line. A logistic model was fit to a dataset with the following output: Estimate SE Z Pr(>|Z|) (Intercept) -0.8161 0.086 -9.4895 0 to_multiple -2.5651 0.3052 -8.4047 0 winner 1.5801 0.3156 5.0067 0 format -0.1528 0.1136 -1.3451 0.1786 re_subj -2.8401 0.363 -7.824 0 (a) Write down the model using the coefficients from the model fit.log_odds(spam) = -0.8161 + -2.5651 + to_multiple + 1.5801 winner + -0.1528 format + -2.8401 re_subj(b) Suppose we have an observation where to_multiple=0, winner=1, format=0, and re_subj=0. What is the predicted probability that this message is spam?…arrow_forward
- Consider an event X comprised of three outcomes whose probabilities are 9/18, 1/18,and 6/18. Compute the probability of the complement of the event. Question content area bottom Part 1 A.1/2 B.2/18 C.16/18 D.16/3arrow_forwardJohn and Mike were offered mints. What is the probability that at least John or Mike would respond favorably? (Hint: Use the classical definition.) Question content area bottom Part 1 A.1/2 B.3/4 C.1/8 D.3/8arrow_forwardThe details of the clock sales at a supermarket for the past 6 weeks are shown in the table below. The time series appears to be relatively stable, without trend, seasonal, or cyclical effects. The simple moving average value of k is set at 2. What is the simple moving average root mean square error? Round to two decimal places. Week Units sold 1 88 2 44 3 54 4 65 5 72 6 85 Question content area bottom Part 1 A. 207.13 B. 20.12 C. 14.39 D. 0.21arrow_forward
 Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL