
Videos
The business problem facing a consumer products company is to measures the effectiveness of difference types of advertising media in the promotion of its products. Specifically, the company is interested in the effectiveness of ratio advertising and newspaper advertising (including the cost of discount coupons). During a one-month test period, data were collected from a sample of 22 cities with approximately equal populations. Each city is allocated a specific expenditure level for radio advertising and for newspaper advertising. The sales of the product (in thousands of dollars) and also the levels of media expenditure (in thousands of dollars) during the test month are recorded and stored a Advertise.
a. Using all the data as the training sample, develop a regression tree model to predict the sales of the product.
b. What conclusions can you reach about the sales of the product?
a.
Develop a regression tree model to predict the sales of product.
Explanation of Solution
Use JMP to develop a regression tree model.
Software procedure:
Step by step by procedure to develop regression tree is given below:
Open Advertise file in JMP.
Select Analyze > Predictive Modelling > Partition.
Drag Sales to the Y, Response box.
Drag Radio to the X, Factor box.
Drag Newspaper to the X, Factor box.
Click Ok.
Click Split. Repeat this step until clicking Split no longer has any effect on the tree diagram.
The JMP result is shown below:
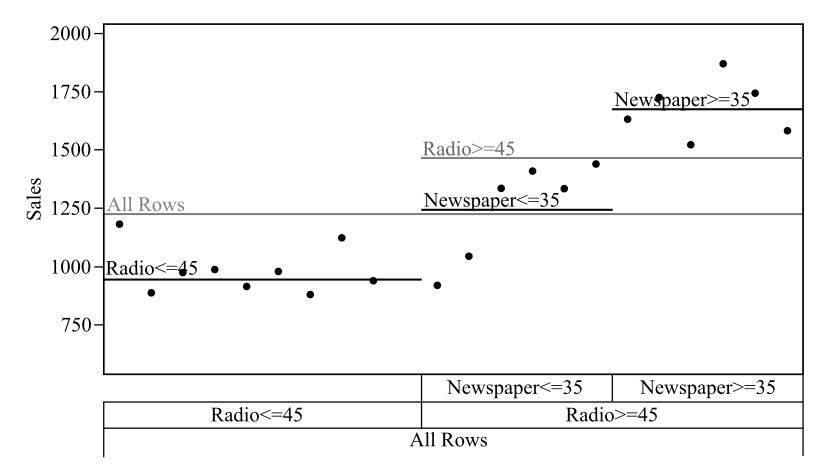
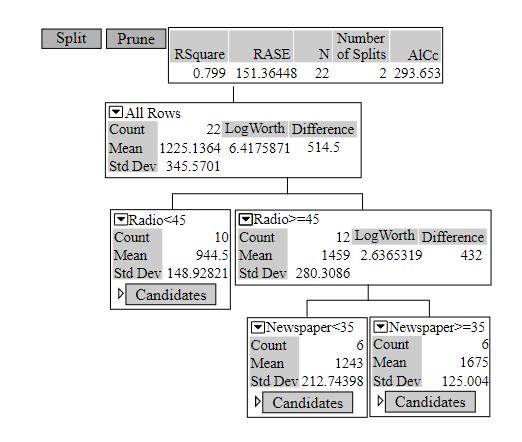
b.
Write conclusion about the sales of product.
Explanation of Solution
The tree model contains two splits and an
At the root node, the data has been split based on whether the radio expenditure is less than 45000 dollars or not. The subset less than 45000 dollars has a count of 10 cities with mean sales of 944.5 thousand dollars, which is less than the other subset having a count of 12 cities with mean 1459 thousand dollars.
The subset radio expenditure greater than 45000 dollars has been further split into two based on whether the newspaper expenditure is less than 35000 dollars or not and each further split has a count of 6 cities. The mean sales of newspaper expenditure less than 35000 dollars is less than the newspaper expenditure of 35000 or more.
Want to see more full solutions like this?
Chapter 17 Solutions
EP BASIC BUS.STATS-ACCESS (18 WEEKS)


- 2 (Normal Distribution) Let rt be a log return. Suppose that r₁, 2, ... are IID N(0.06, 0.47). What is the distribution of rt (4) = rt + rt-1 + rt-2 + rt-3? What is P(rt (4) < 2)? What is the covariance between r2(2) = 1 + 12 and 13(2) = r² + 13? • What is the conditional distribution of r₁(3) = rt + rt-1 + rt-2 given rt-2 = 0.6?arrow_forward3 (Sharpe-ratio) Suppose that X1, X2,..., is a lognormal geometric random walk with parameters (μ, o²). Specifically, suppose that X = Xo exp(rı + ...Tk), where Xo is a fixed constant and r1, T2, ... are IID N(μ, o²). Find the Sharpe-ratios of rk and log(Xk) — log(Xo) respectively, assuming the risk free return is 0.arrow_forwardi need help with question 2arrow_forward
- 4 (Value-at-Risk and Expected Shortfall) Suppose X Find VaR0.02(X) and ES0.02 (X). ~ Uniform(-1, 1).arrow_forward亚 ח Variables Name avgdr employ educ exerany Label AVG ALCOHOLIC DRINKS PER DAY IN PAST 30 EMPLOYMENT STATUS EDUCATION LEVEL EXERCISE IN PAST 30 DAYSarrow_forwardVariables Name wage hours IQ KWW educ exper tenure age married black south urban sibs brthord meduc feduc Label monthly earnings average weekly hours IQ score knowledge of world work score years of education years of work experience years with current employer age in years =1 if married =1 if black =1 if live in south =1 if live in SMSA number of siblings birth order mother's education father's educationarrow_forward
- Information for questions 4 • • Please Download "wages" from Canvas (the link to this dataset is right below the HWA1 questions - it is a Microsoft excel worksheet) and store it in your favorite folder. It contains 797 observations and 16 variables. The "state" variable gives the names of the states involved in this dataset. • You need to have excel on your computer to open this dataset. i. You should use File > Import > Excel Spreadsheet etc. as done in class 3 convert this file into a Stata dataset. Once you are done, write the final STATA code that makes the transformation of an excel file to a STATA file possible. ii. Write a code that will close the log file that has been open since Question 1 part ii.arrow_forwardThe mean, variance, skewness and kurtosis of a dataset are given as - Mean = 15, Variance = 20, SKewness = 1.5 and Kurtosis = 3.5 calculate the first four raw moments. (Note- Please include as much detailed solution/steps in the solution to understand, Thank you!)arrow_forwardWrite codes to perform the functions in each of these cases i. ii. Apply cd command to tell STATA the filepath associated with your "favorite folder" (use the same name for the favorite folder that we have been using in class) Apply log using command to tell stata that you are creating a log file to record the codes and the outcomes of these codes. Make sure your log file is called loghwa1_W25.smcl. Do not forget to include the replace option. iii. Get help for the "regress" command & include a screenshot of the outcome of this code iv. V. Open a stata file stored in STATA memory called pop2000.dta Continue from question iv. Save this file in your favorite folder (current working directory) using a different name & a replace optionarrow_forward
- Are there any unusually high or low pH levels in this sample of wells?arrow_forward0 n AM RIES s of of 10 m Frequency 40 Frequency 20 20 30 10 You make two histograms from two different data sets (see the following figures), each one containing 200 observations. Which of the histograms has a smaller spread: the first or the second? 40 30 20 10 0 20 40 60 0 20 20 40 60 60 80 80 100 80 100arrow_forwardTIP the aren't, the data are not sym 11 Suppose that the average salary at a certain company is $100,000, and the median salary is $40,000. a. What do these figures tell you about the shape of the histogram of salaries at this company? b. Which measure of center is more appro- priate here? c. Suppose that the company goes through a salary negotiation. How can people on each side use these summary statistics to their advantage? 6360 be 52 PART 1 Getting Off to a Statistically Significant Sarrow_forward
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning
Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning