
(a)
To find out what is the sampling distribution of the
(a)
Answer to Problem 14.10AYK
The sampling distribution of the mean blood arsenic concentration
Explanation of Solution
It is given in the question that Arsenic blood concentrations in healthy individuals are
Now, we know that the mean blood arsenic concentration
Thus, we have,
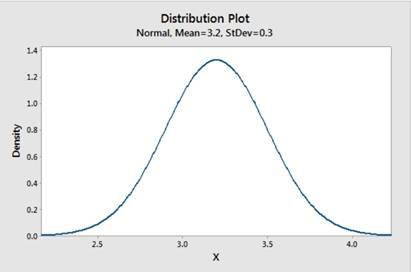
And the sketch of the density curve of this distribution is as follows:
(b)
To obtain P-value for this area and what would we conclude.
(b)
Answer to Problem 14.10AYK
The P-value is
Explanation of Solution
It is given in the question that Arsenic blood concentrations in healthy individuals are normally distributed with mean
And
Now, the first SRS gives,
So, we have the test statistics value and P-value as:
As we know that if the P-value is less than or equal to the significance level then the null hypothesis is rejected, so we have,
Thus, we conclude that we fail to reject the null hypothesis and there is no evidence that there is statistical difference.
(c)
To find out what would be the P-value for this area and what would we conclude.
(c)
Answer to Problem 14.10AYK
The P-value is
Explanation of Solution
It is given in the question that Arsenic blood concentrations in healthy individuals are normally distributed with mean
And
Now, the second SRS gives,
So, we have the test statistics value and P-value as:
As we know that if the P-value is less than or equal to the significance level then the null hypothesis is rejected, so we have,
Thus, we conclude that we fail to reject the null hypothesis and there is no evidence that there is statistical difference.
(d)
To explain briefly why these P-valuestell us that one outcome is strong evidence against the null hypothesis and that the other outcome is not.
(d)
Explanation of Solution
It is given in the question that Arsenic blood concentrations in healthy individuals are normally distributed with mean
And
Now, from the first SRS we get the P-value
Want to see more full solutions like this?
Chapter 14 Solutions
PRACT STAT W/ ACCESS 6MO LOOSELEAF

- Question 1. Your manager asks you to explain why the Black-Scholes model may be inappro- priate for pricing options in practice. Give one reason that would substantiate this claim? Question 2. We consider stock #1 and stock #2 in the model of Problem 2. Your manager asks you to pick only one of them to invest in based on the model provided. Which one do you choose and why ? Question 3. Let (St) to be an asset modeled by the Black-Scholes SDE. Let Ft be the price at time t of a European put with maturity T and strike price K. Then, the discounted option price process (ert Ft) t20 is a martingale. True or False? (Explain your answer.) Question 4. You are considering pricing an American put option using a Black-Scholes model for the underlying stock. An explicit formula for the price doesn't exist. In just a few words (no more than 2 sentences), explain how you would proceed to price it. Question 5. We model a short rate with a Ho-Lee model drt = ln(1+t) dt +2dWt. Then the interest rate…arrow_forwardIn this problem, we consider a Brownian motion (W+) t≥0. We consider a stock model (St)t>0 given (under the measure P) by d.St 0.03 St dt + 0.2 St dwt, with So 2. We assume that the interest rate is r = 0.06. The purpose of this problem is to price an option on this stock (which we name cubic put). This option is European-type, with maturity 3 months (i.e. T = 0.25 years), and payoff given by F = (8-5)+ (a) Write the Stochastic Differential Equation satisfied by (St) under the risk-neutral measure Q. (You don't need to prove it, simply give the answer.) (b) Give the price of a regular European put on (St) with maturity 3 months and strike K = 2. (c) Let X = S. Find the Stochastic Differential Equation satisfied by the process (Xt) under the measure Q. (d) Find an explicit expression for X₁ = S3 under measure Q. (e) Using the results above, find the price of the cubic put option mentioned above. (f) Is the price in (e) the same as in question (b)? (Explain why.)arrow_forwardThe managing director of a consulting group has the accompanying monthly data on total overhead costs and professional labor hours to bill to clients. Complete parts a through c. Question content area bottom Part 1 a. Develop a simple linear regression model between billable hours and overhead costs. Overhead Costsequals=212495.2212495.2plus+left parenthesis 42.4857 right parenthesis42.485742.4857times×Billable Hours (Round the constant to one decimal place as needed. Round the coefficient to four decimal places as needed. Do not include the $ symbol in your answers.) Part 2 b. Interpret the coefficients of your regression model. Specifically, what does the fixed component of the model mean to the consulting firm? Interpret the fixed term, b 0b0, if appropriate. Choose the correct answer below. A. The value of b 0b0 is the predicted billable hours for an overhead cost of 0 dollars. B. It is not appropriate to interpret b 0b0, because its value…arrow_forward
- Using the accompanying Home Market Value data and associated regression line, Market ValueMarket Valueequals=$28,416+$37.066×Square Feet, compute the errors associated with each observation using the formula e Subscript ieiequals=Upper Y Subscript iYiminus−ModifyingAbove Upper Y with caret Subscript iYi and construct a frequency distribution and histogram. LOADING... Click the icon to view the Home Market Value data. Question content area bottom Part 1 Construct a frequency distribution of the errors, e Subscript iei. (Type whole numbers.) Error Frequency minus−15 comma 00015,000less than< e Subscript iei less than or equals≤minus−10 comma 00010,000 0 minus−10 comma 00010,000less than< e Subscript iei less than or equals≤minus−50005000 5 minus−50005000less than< e Subscript iei less than or equals≤0 21 0less than< e Subscript iei less than or equals≤50005000 9…arrow_forwardThe managing director of a consulting group has the accompanying monthly data on total overhead costs and professional labor hours to bill to clients. Complete parts a through c Overhead Costs Billable Hours345000 3000385000 4000410000 5000462000 6000530000 7000545000 8000arrow_forwardUsing the accompanying Home Market Value data and associated regression line, Market ValueMarket Valueequals=$28,416plus+$37.066×Square Feet, compute the errors associated with each observation using the formula e Subscript ieiequals=Upper Y Subscript iYiminus−ModifyingAbove Upper Y with caret Subscript iYi and construct a frequency distribution and histogram. Square Feet Market Value1813 911001916 1043001842 934001814 909001836 1020002030 1085001731 877001852 960001793 893001665 884001852 1009001619 967001690 876002370 1139002373 1131001666 875002122 1161001619 946001729 863001667 871001522 833001484 798001589 814001600 871001484 825001483 787001522 877001703 942001485 820001468 881001519 882001518 885001483 765001522 844001668 909001587 810001782 912001483 812001519 1007001522 872001684 966001581 86200arrow_forward
- For a binary asymmetric channel with Py|X(0|1) = 0.1 and Py|X(1|0) = 0.2; PX(0) = 0.4 isthe probability of a bit of “0” being transmitted. X is the transmitted digit, and Y is the received digit.a. Find the values of Py(0) and Py(1).b. What is the probability that only 0s will be received for a sequence of 10 digits transmitted?c. What is the probability that 8 1s and 2 0s will be received for the same sequence of 10 digits?d. What is the probability that at least 5 0s will be received for the same sequence of 10 digits?arrow_forwardV2 360 Step down + I₁ = I2 10KVA 120V 10KVA 1₂ = 360-120 or 2nd Ratio's V₂ m 120 Ratio= 360 √2 H I2 I, + I2 120arrow_forwardQ2. [20 points] An amplitude X of a Gaussian signal x(t) has a mean value of 2 and an RMS value of √(10), i.e. square root of 10. Determine the PDF of x(t).arrow_forward
 MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman