
Concept explainers
Videos
Speed and density The following data relate traffic Density (measured as number of cars per mile) and the average Speed of traffic (in mph) on city highways. The data were collected at the same location at 10 different times randomly selected within a span of 3 months.
| Density | Speed | |
| 69 | 25.4 | |
| 56 | 32.5 | |
| 62 | 28.6 | |
| 119 | 11.5 | |
| 84 | 21.3 | |
| 74 | 22.1 | |
| 73 | 22.3 | |
| 90 | 18.5 | |
| 38 | 37.2 | |
| 22 | 44.6 | |
| Mean | 68.7 | 26.4 |
| SD | 27.07 | 9.64 |
- a) Describe the relationship between Speed and Density.
- b) Fit a model to predict Speed from Density. Comment on the appropriateness of the model.
- c) If the traffic density is 56 cars/mile and you observe a speed of 32.5 mph, what is the residual? What is the residual for an observed speed of 36.1 mph with a traffic density of 20 cars/mile?
- d) Which of the two residuals in part c is more unusual? Explain.
- e) A new data point has come in. For this observation, Density = 125 cars/mile and Speed = 55 mph. What would happen to the slope and the
correlation if this point were included? - f) Predict the speed of traffic for a density of 200 cars/mile. Is your prediction reasonable? Explain briefly.
- g) If you standardize both variables, what equation predicts the standardized speed from the standardized density?
- h) If you standardize both variables, what equation predicts the standardized density from the standardized speed?
a.
Explain the relationship between speed and density.
Explanation of Solution
Given info:
The data related to the speed and density of traffic at the same location of a city at 10 different times within a span of 3 months.
Calculation:
Scatterplot:
Software procedure:
Step by step procedure to draw scatterplot using MINITAB software is given as,
- Choose Graph > Scatterplot.
- Choose Simple, and then click OK.
- In Y-variables, enter the column of Speed.
- In X-variables enter the column of Density.
- Click OK.
Output using MINITAB software is given as,
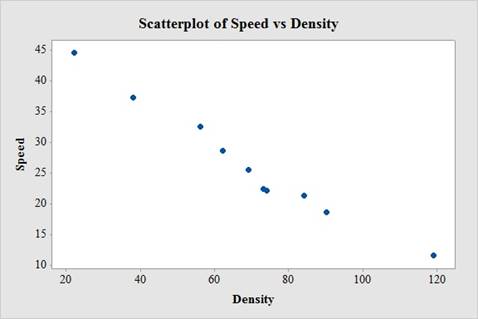
The relation between speed and density is strong, negative and linear. Thus, the association between speed and density is associated with lower speeds.
b.
Obtain a linear model to predict speed from density and comment on the appropriateness of the model.
Answer to Problem 4E
The regression equation of linear model is
Explanation of Solution
Calculation:
Linear regression model:
A linear regression model is given as
Regression
Software procedure:
Step by step procedure to get the output using MINITAB software is given as,
- Choose Stat > Regression > Regression > Fit Regression Model.
- Under Responses, enter the column of Speed.
- Under predictors, enter the columns of Density.
- Click OK.
Output using MINITAB software is given below:

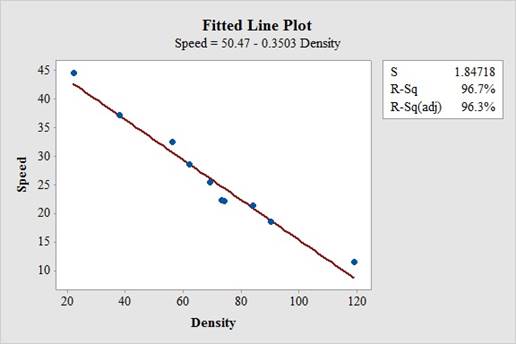
Thus, the regression equation of linear model is
The fitted scatterplot of re-expressed data exhibits a linear pattern. Thus, there is a strong and negative linear association between speed and density of traffic
The coefficient of determination (
In the given output,
Thus, the percentage of variation in the observed values of speed of traffic that is explained by the regression is 96.7%, which indicates that 96.7% of the variability in speed is explained by the variability in density using linear regression model.
The conditions for a residual plot that is well fitted for the data are,
- There should not any bend, which would violate the straight enough condition.
- There must not any outlier, which, were not clear before.
- There should not any change in the spread of the residuals from one part to another part of the plot.
Residual plot:
Software procedure:
Step by step procedure to get the output using MINITAB software is given as,
- Choose Stat > Regression > Regression > Fit Regression Model.
- Under Responses, enter the column of Speed.
- Under Continuous predictors, enter the columns of Density.
- In Graphs, under Residuals for plots choose Regular.
- Under Residuals plots choose Individuals plots and select box of Residuals versus fits.
- Click OK.
Output using MINITAB software is given below:
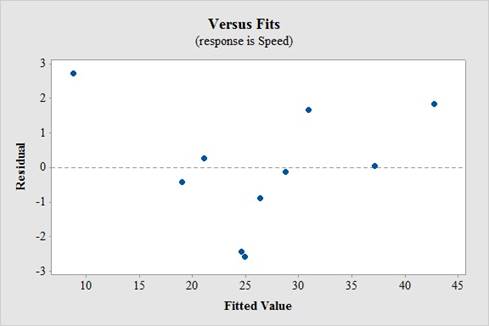
In residual plot, there is no bend or pattern, which can violate the straight enough condition and there is no change in the spread of the residuals from one part to another part of the plot.
Thus, a linear model is appropriated.
c.
Find the residual of a traffic, having density and observed speed of 56 cars/mile and 32.5 mph, respectively.
Find the residual of another traffic, having density and observed speed of 20 cars/mile and 36.1 mph, respectively.
Answer to Problem 4E
The residual of a traffic, having density and observed speed of 56 cars/mile and 32.5 mph, respectively is 1.65 mph and the residual of a traffic, having density and observed speed of 20 cars/mile and 36.1 mph, respectively is –7.36 mph.
Explanation of Solution
Calculation:
Assume x be the predictor variable and y be the response variable, of a regression analysis. Then, the predicted value of the response variable is
Residual:
The residual is defined as
If the observed value is less than predicted value then the residual will be negative and if the observed value is greater than predicted value then the residual will be positive.
From the previous part b. it is found that the regression equation of linear model is
The predicted speed of a traffic having density of 56 cars/mile is,
Thus, the predicted speed of a traffic having density of 56 cars/mile is 30.8532 mph.
It is known, that actual speed of a traffic having density of 56 cars/mile is 32.5 mph.
The value of the residual is,
Thus, the residual of a traffic, having density and observed speed of 56 cars/mile and 32.5 mph, respectively is 1.65 mph.
The predicted speed of a traffic having density of 20 cars/mile is,
Thus, the predicted speed of a traffic having density of 20 cars/mile is 43.46 mph.
It is known, that actual speed of a traffic having density of 20 cars/mile is 36.1 mph.
The value of the residual is,
Thus, the residual of a traffic, having density and observed speed of 20 cars/mile and 36.1 mph, respectively is –7.36 mph.
d.
Find the unusual residual.
Answer to Problem 4E
Second residual is more unusual residual.
Explanation of Solution
From previous part c. it is found that residual of a traffic, having density and observed speed of 56 cars/mile and 32.5 mph, respectively is 1.65 mph and the residual of a traffic, having density and observed speed of 20 cars/mile and 36.1 mph, respectively is –7.36 mph.
Thus, it is clear that the second residual value is far away from the predicted value. Therefore, second residual is more unusual residual.
e.
Explain about slope and the correlation if the new point
Explanation of Solution
The new point
In another words, shallower slope and weaker correlation are closer to 0 as they are both started as negative quantity.
Thus, technically slope and correlation becomes higher.
f.
Predict the speed of traffic for a density of 200 cars/mile.
Explain whether the prediction is reasonable.
Answer to Problem 4E
The predicted speed of a traffic having density of 200 cars/mile is –19.6 mph.
Explanation of Solution
Calculation:
The predicted speed of a traffic having density of 200 cars/mile is,
Thus, the predicted speed of a traffic having density of 200 cars/mile is –19.6 mph.
This result is not meaningful as the value of the speed comes as negative quantity, which cannot be possible. Moreover, the given car density of 200 cars/mile is far beyond from the observed values.
Thus, the prediction is not reasonable.
g.
Find the equation to predict the standardized speed from the standardized density if both the variables are standardized.
Answer to Problem 4E
The equation to predict the standardized speed from the standardized density is
Explanation of Solution
Calculation:
z-score:
The z-score of a random variable x is defined as
Correlation coefficient:
Software Procedure:
Step by step procedure to obtain the correlation coefficient of the data using the MINITAB software:
- Choose Stat > Basic Statistics > Correlation.
- In Variables, enter the column of Speed and Density.
- Click OK in all dialogue boxes.
Output using the MINITAB software is given below:

Thus, the correlation confident for speed and density is –0.984.
It is known that, the slope
Now, for the predictor variable x and response variable y also scarify the regression equation
Consider, the mean of the predictor variable x is
Subtract the equation
Using the formula
In this problem, as speed is the predictor variable (x) and density of traffic is response variable (y) with the correlation coefficient of
h.
Find the equation to predict the standardized density from the standardized speed if both the variables are standardized.
Answer to Problem 4E
The equation to predict the standardized density from the standardized speed is
Explanation of Solution
Calculation:
From the previous part g. it is found that the correlation confident for speed and density is –0.984. In addition correlation is same regardless of the direction of prediction.
Consider, the mean of the predictor variable x is
Subtract the equation
Using the formula
In this problem, as density is the predictor variable (x) and speed of traffic is response variable (y) with the correlation coefficient of
Want to see more full solutions like this?
Chapter CR Solutions
Intro Stats, Books a la Carte Edition (5th Edition)


- ian income of $50,000. erty rate of 13. Using data from 50 workers, a researcher estimates Wage = Bo+B,Education + B₂Experience + B3Age+e, where Wage is the hourly wage rate and Education, Experience, and Age are the years of higher education, the years of experience, and the age of the worker, respectively. A portion of the regression results is shown in the following table. ni ogolloo bash 1 Standard Coefficients error t stat p-value Intercept 7.87 4.09 1.93 0.0603 Education 1.44 0.34 4.24 0.0001 Experience 0.45 0.14 3.16 0.0028 Age -0.01 0.08 -0.14 0.8920 a. Interpret the estimated coefficients for Education and Experience. b. Predict the hourly wage rate for a 30-year-old worker with four years of higher education and three years of experience.arrow_forward1. If a firm spends more on advertising, is it likely to increase sales? Data on annual sales (in $100,000s) and advertising expenditures (in $10,000s) were collected for 20 firms in order to estimate the model Sales = Po + B₁Advertising + ε. A portion of the regression results is shown in the accompanying table. Intercept Advertising Standard Coefficients Error t Stat p-value -7.42 1.46 -5.09 7.66E-05 0.42 0.05 8.70 7.26E-08 a. Interpret the estimated slope coefficient. b. What is the sample regression equation? C. Predict the sales for a firm that spends $500,000 annually on advertising.arrow_forwardCan you help me solve problem 38 with steps im stuck.arrow_forward
- How do the samples hold up to the efficiency test? What percentages of the samples pass or fail the test? What would be the likelihood of having the following specific number of efficiency test failures in the next 300 processors tested? 1 failures, 5 failures, 10 failures and 20 failures.arrow_forwardThe battery temperatures are a major concern for us. Can you analyze and describe the sample data? What are the average and median temperatures? How much variability is there in the temperatures? Is there anything that stands out? Our engineers’ assumption is that the temperature data is normally distributed. If that is the case, what would be the likelihood that the Safety Zone temperature will exceed 5.15 degrees? What is the probability that the Safety Zone temperature will be less than 4.65 degrees? What is the actual percentage of samples that exceed 5.25 degrees or are less than 4.75 degrees? Is the manufacturing process producing units with stable Safety Zone temperatures? Can you check if there are any apparent changes in the temperature pattern? Are there any outliers? A closer look at the Z-scores should help you in this regard.arrow_forwardNeed help pleasearrow_forward
- Please conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. 4. One-Way ANOVA: Analyze the customer satisfaction scores across four different product categories to determine if there is a significant difference in means. (Hints: The null can be about maintaining status-quo or no difference among groups) H0 = H1=arrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points 2. Two-Sample T-Test: Compare the average sales revenue of two different regions to determine if there is a significant difference. (Hints: The null can be about maintaining status-quo or no difference among groups; if alternative hypothesis is non-directional use the two-tailed p-value from excel file to make a decision about rejecting or not rejecting null) H0 = H1=arrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points 3. Paired T-Test: A company implemented a training program to improve employee performance. To evaluate the effectiveness of the program, the company recorded the test scores of 25 employees before and after the training. Determine if the training program is effective in terms of scores of participants before and after the training. (Hints: The null can be about maintaining status-quo or no difference among groups; if alternative hypothesis is non-directional, use the two-tailed p-value from excel file to make a decision about rejecting or not rejecting the null) H0 = H1= Conclusion:arrow_forward
- Please conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. The data for the following questions is provided in Microsoft Excel file on 4 separate sheets. Please conduct these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. 1. One Sample T-Test: Determine whether the average satisfaction rating of customers for a product is significantly different from a hypothetical mean of 75. (Hints: The null can be about maintaining status-quo or no difference; If your alternative hypothesis is non-directional (e.g., μ≠75), you should use the two-tailed p-value from excel file to…arrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. 1. One Sample T-Test: Determine whether the average satisfaction rating of customers for a product is significantly different from a hypothetical mean of 75. (Hints: The null can be about maintaining status-quo or no difference; If your alternative hypothesis is non-directional (e.g., μ≠75), you should use the two-tailed p-value from excel file to make a decision about rejecting or not rejecting null. If alternative is directional (e.g., μ < 75), you should use the lower-tailed p-value. For alternative hypothesis μ > 75, you should use the upper-tailed p-value.) H0 = H1= Conclusion: The p value from one sample t-test is _______. Since the two-tailed p-value is _______ 2. Two-Sample T-Test:…arrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. What is one sample T-test? Give an example of business application of this test? What is Two-Sample T-Test. Give an example of business application of this test? .What is paired T-test. Give an example of business application of this test? What is one way ANOVA test. Give an example of business application of this test? 1. One Sample T-Test: Determine whether the average satisfaction rating of customers for a product is significantly different from a hypothetical mean of 75. (Hints: The null can be about maintaining status-quo or no difference; If your alternative hypothesis is non-directional (e.g., μ≠75), you should use the two-tailed p-value from excel file to make a decision about rejecting or not…arrow_forward
 Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning
Functions and Change: A Modeling Approach to Coll...AlgebraISBN:9781337111348Author:Bruce Crauder, Benny Evans, Alan NoellPublisher:Cengage Learning Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt