
a.
To find: histogram of the given data and also plot the relative frequencies and explain the distribution of weights of newborn babies.
a.
Explanation of Solution
Given:
The dataset:
| Weight(Grams) | Count |
| Less than 500 | 5980 |
| 500 - 999 | 22015 |
| 1000 - 1499 | 29846 |
| 1500 - 1999 | 63427 |
| 2000 - 2499 | 204295 |
| 2500 - 2999 | 744181 |
| 3000 - 3499 | 1566755 |
| 3500 - 3999 | 1055004 |
| 4000 - 4499 | 262997 |
| 4500 - 4999 | 36706 |
| 5000 - 5499 | 4216 |
Formula used:
Calculation:
| Weight(Grams) | Relative frequency |
| Less than 500 | 0.001 |
| 500 - 999 | 0.006 |
| 1000 - 1499 | 0.007 |
| 1500 - 1999 | 0.016 |
| 2000 - 2499 | 0.051 |
| 2500 - 2999 | 0.186 |
| 3000 - 3499 | 0.392 |
| 3500 - 3999 | 0.264 |
| 4000 - 4499 | 0.066 |
| 4500 - 4999 | 0.009 |
| 5000 - 5499 | 0.001 |
| Sum | 1 |
Graph:
The histogram:
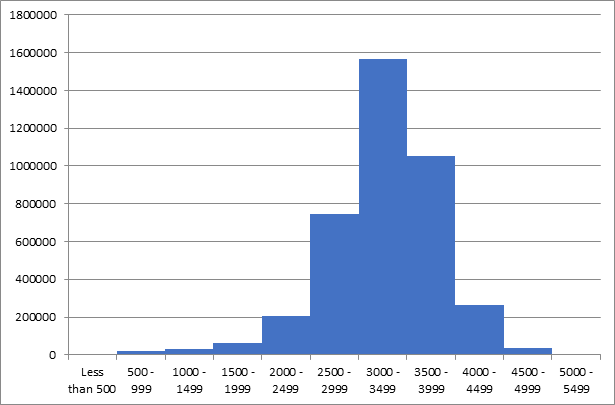
The relative frequency histogram:
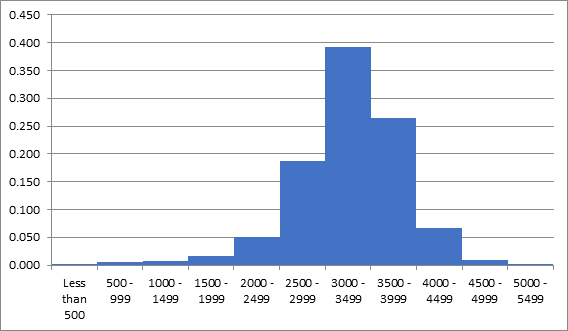
Based on the above histogram, it looks that data is approximately
b.
To find the
b.
Explanation of Solution
Formula used:
Calculation:
| Weight(Grams) | Count | Cumulative frequency. |
| Less than 500 | 5980 | 5980 |
| 500 - 999 | 22015 | 27995 |
| 1000 - 1499 | 29846 | 57841 |
| 1500 - 1999 | 63427 | 121268 |
| 2000 - 2499 | 204295 | 325563 |
| 2500 - 2999 | 744181 | 1069744 |
| 3000 - 3499 | 1566755 | 2636499 |
| 3500 - 3999 | 1055004 | 3691503 |
| 4000 - 4499 | 262997 | 3954500 |
| 4500 - 4999 | 36706 | 3991206 |
| 5000 - 5499 | 4216 | 3995422 |
| Sum | 3995422 |
Median =
Now, it required to see that in under which CF value does it falls.
The value 1997711 is less than 2636499, so the median value falls in the class 3000 − 3499.
c.
To construct the pie chart or bar chart to show the proportion of given categories.
c.
Explanation of Solution
Given:
The categories:
Very low birth weight: Less than 1500 grams
Low birth weight: Less than 2500 grams
Normal birth weight: More than 2500 grams
Calculation:
Count of each category:
| Category | Frequency | Proportion |
| Very low birth Weight | 57841 | 0.0144768 |
| Low birth weight | 267722 | 0.0670072 |
| Normal birth weight | 3669859 | 0.918516 |
Graph:
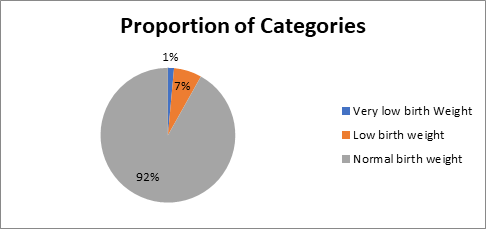
d.
To explain the outcome of the analysis that is being done so far.
d.
Explanation of Solution
Based on the graph prepared in the last part, it is clearly visible that about 8% child having risk of low weight at the time of birth, which indicates at huge proportion of total, it is not an unusual
Want to see more full solutions like this?
Chapter 8 Solutions
PRACT STAT W/ ACCESS 6MO LOOSELEAF

- Please help me answer the following questions from this problem.arrow_forwardPlease help me find the sample variance for this question.arrow_forwardCrumbs Cookies was interested in seeing if there was an association between cookie flavor and whether or not there was frosting. Given are the results of the last week's orders. Frosting No Frosting Total Sugar Cookie 50 Red Velvet 66 136 Chocolate Chip 58 Total 220 400 Which category has the greatest joint frequency? Chocolate chip cookies with frosting Sugar cookies with no frosting Chocolate chip cookies Cookies with frostingarrow_forward
- The table given shows the length, in feet, of dolphins at an aquarium. 7 15 10 18 18 15 9 22 Are there any outliers in the data? There is an outlier at 22 feet. There is an outlier at 7 feet. There are outliers at 7 and 22 feet. There are no outliers.arrow_forwardStart by summarizing the key events in a clear and persuasive manner on the article Endrikat, J., Guenther, T. W., & Titus, R. (2020). Consequences of Strategic Performance Measurement Systems: A Meta-Analytic Review. Journal of Management Accounting Research?arrow_forwardThe table below was compiled for a middle school from the 2003 English/Language Arts PACT exam. Grade 6 7 8 Below Basic 60 62 76 Basic 87 134 140 Proficient 87 102 100 Advanced 42 24 21 Partition the likelihood ratio test statistic into 6 independent 1 df components. What conclusions can you draw from these components?arrow_forward
- What is the value of the maximum likelihood estimate, θ, of θ based on these data? Justify your answer. What does the value of θ suggest about the value of θ for this biased die compared with the value of θ associated with a fair, unbiased, die?arrow_forwardShow that L′(θ) = Cθ394(1 −2θ)604(395 −2000θ).arrow_forwarda) Let X and Y be independent random variables both with the same mean µ=0. Define a new random variable W = aX +bY, where a and b are constants. (i) Obtain an expression for E(W).arrow_forward
- The table below shows the estimated effects for a logistic regression model with squamous cell esophageal cancer (Y = 1, yes; Y = 0, no) as the response. Smoking status (S) equals 1 for at least one pack per day and 0 otherwise, alcohol consumption (A) equals the average number of alcohoic drinks consumed per day, and race (R) equals 1 for blacks and 0 for whites. Variable Effect (β) P-value Intercept -7.00 <0.01 Alcohol use 0.10 0.03 Smoking 1.20 <0.01 Race 0.30 0.02 Race × smoking 0.20 0.04 Write-out the prediction equation (i.e., the logistic regression model) when R = 0 and again when R = 1. Find the fitted Y S conditional odds ratio in each case. Next, write-out the logistic regression model when S = 0 and again when S = 1. Find the fitted Y R conditional odds ratio in each case.arrow_forwardThe chi-squared goodness-of-fit test can be used to test if data comes from a specific continuous distribution by binning the data to make it categorical. Using the OpenIntro Statistics county_complete dataset, test the hypothesis that the persons_per_household 2019 values come from a normal distribution with mean and standard deviation equal to that variable's mean and standard deviation. Use signficance level a = 0.01. In your solution you should 1. Formulate the hypotheses 2. Fill in this table Range (-⁰⁰, 2.34] (2.34, 2.81] (2.81, 3.27] (3.27,00) Observed 802 Expected 854.2 The first row has been filled in. That should give you a hint for how to calculate the expected frequencies. Remember that the expected frequencies are calculated under the assumption that the null hypothesis is true. FYI, the bounderies for each range were obtained using JASP's drag-and-drop cut function with 8 levels. Then some of the groups were merged. 3. Check any conditions required by the chi-squared…arrow_forwardSuppose that you want to estimate the mean monthly gross income of all households in your local community. You decide to estimate this population parameter by calling 150 randomly selected residents and asking each individual to report the household’s monthly income. Assume that you use the local phone directory as the frame in selecting the households to be included in your sample. What are some possible sources of error that might arise in your effort to estimate the population mean?arrow_forward
 MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman