
Concept explainers
Videos
Americans Dining Out. Americans tend to dine out multiple times per week. The number of times a sample of 20 families dined out last week provides the following data.
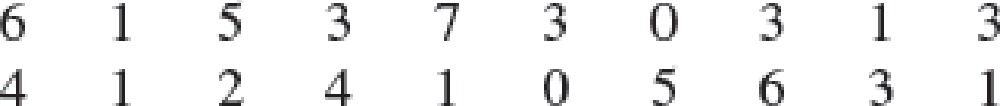
- a. Compute the
mean andmedian . - b. Compute the first and third
quartiles. - c. Compute the
range andinterquartile range . - d. Compute the variance and standard deviation.
- e. The skewness measure for these data is .34. Comment on the shape of this distribution. Is it the shape you would expect? Why or why not?
- f. Do the data contain outliers?
a.
Find the mean and median.
Answer to Problem 62SE
The mean and median are 2.95 and 3, respectively.
Explanation of Solution
Calculation:
The data represent the number of times a family dined out last week for a sample of 20 families.
Descriptive measures:
Software procedure:
Step by step procedure to obtain the descriptive statistics using EXCEL is as follows:
- In an EXCEL sheet enter the data values of the sample and label it as Sample.
- Go to Data > Data Analysis (in case it is not default, take the Analysis ToolPak from Excel Add Ins) > Descriptive statistics.
- Enter Input Range as $A$2:$A$21, select Columns in Grouped By, tick on Summary statistics.
- Click on OK.
Output using EXCEL is given as follows:
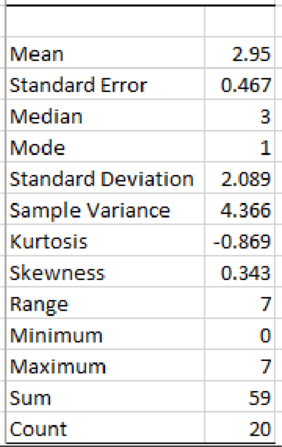
From the EXCEL output, the mean and median number of crossing for these ports of entry are 2.95 and 3, respectively.
Thus, the mean and median are 2.95, and 3, respectively.
b.
Find the first and third quartiles.
Answer to Problem 62SE
The first and third quartiles of the dataset are 1 and 4.75, respectively.
Explanation of Solution
Calculation:
First quartile:
The EXCEL function to compute first quartile is
Software Procedure:
Step by step procedure to obtain the first quartile using EXCEL is as follows:
- Open an EXCEL file.
- Enter the data in the column A in cells A2 to A21.
- In a cell, enter the formula QUARTILE.EXC (A2:A21,1).
- Click on OK.
Output using EXCEL is given as follows:
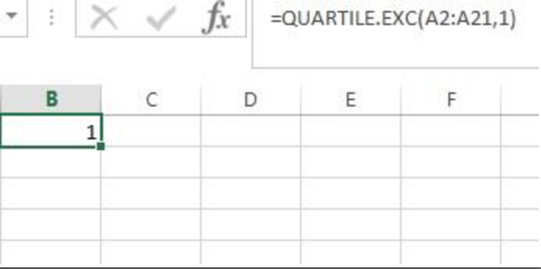
From the EXCEL output, the first quartile of the sample data is 1.
Third quartile:
The EXCEL function to compute third quartile is
Software Procedure:
Step by step procedure to obtain the third quartile using EXCEL is as follows:
- Open an EXCEL file.
- Enter the data in the column A in cells A2 to A21.
- In a cell, enter the formula QUARTILE.EXC (A2:A21,3).
- Click on OK.
Output using EXCEL is given as follows:
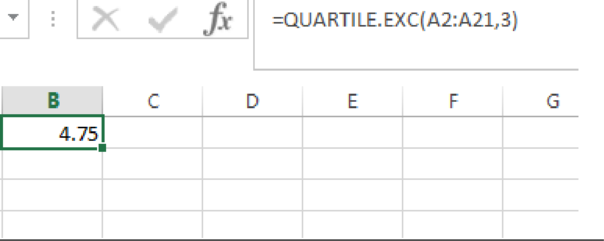
From the EXCEL output, the third quartile of the sample data is 4.75.
Thus, the first and third quartiles are 1 and 4.75, respectively.
c.
Find the range and interquartile range.
Answer to Problem 62SE
The range and interquartile range are 7 and 3.75, respectively.
Explanation of Solution
Calculation:
From the EXCEL output obtained in Part (a), the range of the dataset is 7.
From the answers obtained in Part (b), the first and third quartiles of the dataset are 1 and 4.75, respectively.
The IQR can be obtained as follows:
Substitute
Thus, the IQR is 3.75.
Hence, the range, and interquartile range of the dataset are 7, and 3.75, respectively.
d.
Find the variance and standard deviation.
Answer to Problem 62SE
The variance and standard deviation of the dataset are 4.366 and 2.089, respectively.
Explanation of Solution
Calculation:
From the EXCEL output obtained in Part (a), the variance and standard deviation of the dataset are 4.366 and 2.089, respectively.
Thus, the variance and standard deviation of the dataset are 4.366 and 2.089, respectively.
e.
Comment on the shape of the distribution of the given dataset.
Explain whether or not the obtained shape is expected shape.
Explanation of Solution
Given that, the skewness measure for the data is 0.34.
Skewness:
- If the value of skewness is equal to zero, then the distribution is symmetric.
- If the skewness value is less than zero, then the distribution is negatively skewed
- If the skewness value is greater than zero, then the distribution is positively skewed.
Here, the measure of skewness is 0.34.
Since, the measure of skewness is greater than zero, the shape of the distribution is said to be positively skewed.
f.
Check whether the data contain any outliers.
Answer to Problem 62SE
The data has no outliers.
Explanation of Solution
Calculation:
Outliers:
The outlier is the observational point that is distant from the remaining observational points. In other words, outlier is an observation that lies in an abnormal distance from the remaining values.
The outlier in the dataset is identified using the following calculation.
The formula for lower limit is given below:
Here,
Substitute
Thus, the lower limit is –4.625.
The formula for upper limit is given below:
Substitute
Thus, the upper limit is 10.375.
In the present scenario, the data points that are less than lower limit (–4.625) and the data points that are greater than upper limit (10.375) are considered as outliers.
Here, none of the data points are less than the lower limit (–4.625) and none of the data points are greater than upper limit (10.375).
Since, all the data values lie within the limits.
Thus, the dataset does not contain any outliers.
Want to see more full solutions like this?
Chapter 3 Solutions
Essentials Of Statistics For Business & Economics


- ons 12. A sociologist hypothesizes that the crime rate is higher in areas with higher poverty rate and lower median income. She col- lects data on the crime rate (crimes per 100,000 residents), the poverty rate (in %), and the median income (in $1,000s) from 41 New England cities. A portion of the regression results is shown in the following table. Standard Coefficients error t stat p-value Intercept -301.62 549.71 -0.55 0.5864 Poverty 53.16 14.22 3.74 0.0006 Income 4.95 8.26 0.60 0.5526 a. b. Are the signs as expected on the slope coefficients? Predict the crime rate in an area with a poverty rate of 20% and a median income of $50,000. 3. Using data from 50 workarrow_forward2. The owner of several used-car dealerships believes that the selling price of a used car can best be predicted using the car's age. He uses data on the recent selling price (in $) and age of 20 used sedans to estimate Price = Po + B₁Age + ε. A portion of the regression results is shown in the accompanying table. Standard Coefficients Intercept 21187.94 Error 733.42 t Stat p-value 28.89 1.56E-16 Age -1208.25 128.95 -9.37 2.41E-08 a. What is the estimate for B₁? Interpret this value. b. What is the sample regression equation? C. Predict the selling price of a 5-year-old sedan.arrow_forwardian income of $50,000. erty rate of 13. Using data from 50 workers, a researcher estimates Wage = Bo+B,Education + B₂Experience + B3Age+e, where Wage is the hourly wage rate and Education, Experience, and Age are the years of higher education, the years of experience, and the age of the worker, respectively. A portion of the regression results is shown in the following table. ni ogolloo bash 1 Standard Coefficients error t stat p-value Intercept 7.87 4.09 1.93 0.0603 Education 1.44 0.34 4.24 0.0001 Experience 0.45 0.14 3.16 0.0028 Age -0.01 0.08 -0.14 0.8920 a. Interpret the estimated coefficients for Education and Experience. b. Predict the hourly wage rate for a 30-year-old worker with four years of higher education and three years of experience.arrow_forward
- 1. If a firm spends more on advertising, is it likely to increase sales? Data on annual sales (in $100,000s) and advertising expenditures (in $10,000s) were collected for 20 firms in order to estimate the model Sales = Po + B₁Advertising + ε. A portion of the regression results is shown in the accompanying table. Intercept Advertising Standard Coefficients Error t Stat p-value -7.42 1.46 -5.09 7.66E-05 0.42 0.05 8.70 7.26E-08 a. Interpret the estimated slope coefficient. b. What is the sample regression equation? C. Predict the sales for a firm that spends $500,000 annually on advertising.arrow_forwardCan you help me solve problem 38 with steps im stuck.arrow_forwardHow do the samples hold up to the efficiency test? What percentages of the samples pass or fail the test? What would be the likelihood of having the following specific number of efficiency test failures in the next 300 processors tested? 1 failures, 5 failures, 10 failures and 20 failures.arrow_forward
- The battery temperatures are a major concern for us. Can you analyze and describe the sample data? What are the average and median temperatures? How much variability is there in the temperatures? Is there anything that stands out? Our engineers’ assumption is that the temperature data is normally distributed. If that is the case, what would be the likelihood that the Safety Zone temperature will exceed 5.15 degrees? What is the probability that the Safety Zone temperature will be less than 4.65 degrees? What is the actual percentage of samples that exceed 5.25 degrees or are less than 4.75 degrees? Is the manufacturing process producing units with stable Safety Zone temperatures? Can you check if there are any apparent changes in the temperature pattern? Are there any outliers? A closer look at the Z-scores should help you in this regard.arrow_forwardNeed help pleasearrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. 4. One-Way ANOVA: Analyze the customer satisfaction scores across four different product categories to determine if there is a significant difference in means. (Hints: The null can be about maintaining status-quo or no difference among groups) H0 = H1=arrow_forward
- Please conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points 2. Two-Sample T-Test: Compare the average sales revenue of two different regions to determine if there is a significant difference. (Hints: The null can be about maintaining status-quo or no difference among groups; if alternative hypothesis is non-directional use the two-tailed p-value from excel file to make a decision about rejecting or not rejecting null) H0 = H1=arrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points 3. Paired T-Test: A company implemented a training program to improve employee performance. To evaluate the effectiveness of the program, the company recorded the test scores of 25 employees before and after the training. Determine if the training program is effective in terms of scores of participants before and after the training. (Hints: The null can be about maintaining status-quo or no difference among groups; if alternative hypothesis is non-directional, use the two-tailed p-value from excel file to make a decision about rejecting or not rejecting the null) H0 = H1= Conclusion:arrow_forwardPlease conduct a step by step of these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. The data for the following questions is provided in Microsoft Excel file on 4 separate sheets. Please conduct these statistical tests on separate sheets of Microsoft Excel. If the calculations in Microsoft Excel are incorrect, the null and alternative hypotheses, as well as the conclusions drawn from them, will be meaningless and will not receive any points. 1. One Sample T-Test: Determine whether the average satisfaction rating of customers for a product is significantly different from a hypothetical mean of 75. (Hints: The null can be about maintaining status-quo or no difference; If your alternative hypothesis is non-directional (e.g., μ≠75), you should use the two-tailed p-value from excel file to…arrow_forward
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt