
a.
To construct: A percentile graph for the given data.
a.
Answer to Problem 3.3.23RE
The percentile graph for the given data is as follows,
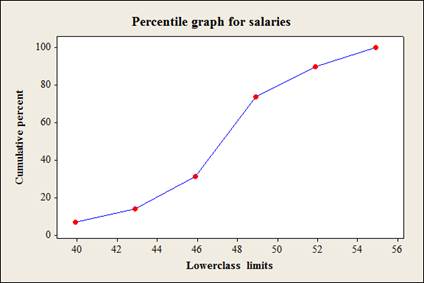
Explanation of Solution
Given info:
The data represents the salaries (in millions of dollars) for 29 NFL teams for the 1999 2000 season.
| Class limits | Frequency |
| 39.9-42.8 | 2 |
| 42.9-45.8 | 2 |
| 45.9-48.8 | 5 |
| 48.9-51.8 | 5 |
| 51.8-54.8 | 12 |
| 54.9-57.8 | 3 |
Calculation:
The cumulative frequency for the distribution is calculated and tabulated below,
| Class limits | Frequency | Cumulative frequency |
| 39.9-42.8 | 2 | 2 |
| 42.9-45.8 | 2 |
|
| 45.9-48.8 | 5 |
|
| 48.9-51.8 | 5 |
|
| 51.8-54.8 | 12 |
|
| 54.9-57.8 | 3 |
|
The formula to calculate the cumulative percentage is as follows,
For the cumulative frequency 2:
Substitute cumulative frequency as 2 and n as 29 in the formula,
Similarly for remaining values the cumulative percent are tabulated below
| Class limit | Frequency |
Cumulative frequency | Cumulative percent |
| 39.9-42.8 | 2 | 2 | 6.89 |
| 42.9-45.8 | 2 | 4 |
|
| 45.9-48.8 | 5 | 9 |
|
| 48.9-51.8 | 5 | 14 |
|
| 51.9-54.8 | 12 | 26 |
|
| 54.9-57.8 | 3 | 29 |
|
|
|
Software procedure:
Step-by-step software procedure to draw ogive curve using MINITAB software is as follows:
- Choose Graph >
Scatter plot . - Choose With Connect Line, and then click OK.
- In Y variables, enter the Cumulative Percent.
- In X variables enter the Lower class limits.
- In Data view, select Symbols and Connect line under Data display.
- In Data view, select Smoother and enter 0 for Degree of smoothing and 1 for Number of steps under Lowness.
- Click OK
- To modify the interval settings, double click on the horizontal axis of the graph. Then, select Labels > Specified. In this box, enter the values for the cutpoints of the bin intervals (39.9, 42.9, 45.9, 48.9, 51.9, 54.9).
b.
The values that correspond to the 35th, 65th and 85th percentiles.
b.
Answer to Problem 3.3.23RE
The values corresponding to 35th, 65th and 85th percentile are 50, 53 and 55.
Explanation of Solution
Calculation:
From part (a) the cumulative percent table is as follows,
| Class limit | Frequency |
Cumulative frequency |
Cumulative percent |
| 39.9-42.8 | 2 | 2 | 6.89 |
| 42.9-45.8 | 2 | 4 | 13.79 |
| 45.9-48.8 | 5 | 9 | 31.03 |
| 48.9-51.8 | 5 | 14 | 73.68 |
| 51.9-54.8 | 12 | 26 | 89.65 |
| 54.9-57.8 | 3 | 29 | 100 |
|
|
For 35th percentile:
The 35th percentile location is calculated below,
Substitute n as 29 and m as 35 in the formula,
Here the 10th observation corresponds to the cumulative frequency 14 which falls in the class 48.9-51.8.
The formula to calculate the percentile for the grouped data is given below,
Where,
- l, the lower limit of the class.
- h, the width of class.
- f, the frequency of the class.
- p, the percentiles rank.
- n is the total number
- c is the preceding cumulative frequency
Substitute 35 for m, 48.9 for
Thus, the 35th percentile of the data is approximately 50.
For 65th percentile:
The 65th percentile location is calculated below,
Substitute n as 29 and m as 65 in the formula,
Here the 19th observation corresponds to the cumulative frequency 26 which falls in the class 51.9-54.8.
Substitute 65 for m, 51.9 for
Thus, the 65th percentile of the data is approximately 53.
For 85th percentile:
The 85th percentile location is calculated below,
Substitute n as 29 and m as 85 in the formula,
Here the 25th observation corresponds to the cumulative frequency 26 which falls in the class 51.9-54.8.
Substitute 85 for m, 51.9 for
Thus, the 85th percentile of the data is approximately 55.
c.
The percentile rank of values 44, 48 and 54.
c.
Answer to Problem 3.3.23RE
The percentile rank for values 44, 48 and 54 are 10th, 26th and 78th respectively.
Explanation of Solution
Calculation:
| Class limit | Frequency |
Cumulative frequency |
| 39.9-42.8 | 2 | 2 |
| 42.9-45.8 | 2 | 4 |
| 45.9-48.8 | 5 | 9 |
| 48.9-51.8 | 5 | 14 |
| 51.9-54.8 | 12 | 26 |
| 54.9-57.8 | 3 | 29 |
|
|
For the value 44:
Here, the value 44 falls in the interval 42.9-45.8.
Substitute 44 for
Thus, the percentile rank for the value 44 is 10th percentile.
For the value 48:
Here, the value 48 falls in the interval 45.9-48.8
Substitute 48 for
Thus, the percentile rank for the value 48 is 26th percentile.
For the value 48:
Here, the value 48 falls in the interval 51.9-54.8
Substitute 54 for
Thus, the percentile rank for the value 54 is 78th percentile
Want to see more full solutions like this?
Chapter 3 Solutions
Bluman, Elementary Statistics: A Step By Step Approach, © 2015, 9e, Student Edition (reinforced Binding) (a/p Statistics)

- 5. Probability Distributions – Continuous Random Variables A factory machine produces metal rods whose lengths (in cm) follow a continuous uniform distribution on the interval [98, 102]. Questions: a) Define the probability density function (PDF) of the rod length.b) Calculate the probability that a randomly selected rod is shorter than 99 cm.c) Determine the expected value and variance of rod lengths.d) If a sample of 25 rods is selected, what is the probability that their average length is between 99.5 cm and 100.5 cm? Justify your answer using the appropriate distribution.arrow_forward2. Hypothesis Testing - Two Sample Means A nutritionist is investigating the effect of two different diet programs, A and B, on weight loss. Two independent samples of adults were randomly assigned to each diet for 12 weeks. The weight losses (in kg) are normally distributed. Sample A: n = 35, 4.8, s = 1.2 Sample B: n=40, 4.3, 8 = 1.0 Questions: a) State the null and alternative hypotheses to test whether there is a significant difference in mean weight loss between the two diet programs. b) Perform a hypothesis test at the 5% significance level and interpret the result. c) Compute a 95% confidence interval for the difference in means and interpret it. d) Discuss assumptions of this test and explain how violations of these assumptions could impact the results.arrow_forward1. Sampling Distribution and the Central Limit Theorem A company produces batteries with a mean lifetime of 300 hours and a standard deviation of 50 hours. The lifetimes are not normally distributed—they are right-skewed due to some batteries lasting unusually long. Suppose a quality control analyst selects a random sample of 64 batteries from a large production batch. Questions: a) Explain whether the distribution of sample means will be approximately normal. Justify your answer using the Central Limit Theorem. b) Compute the mean and standard deviation of the sampling distribution of the sample mean. c) What is the probability that the sample mean lifetime of the 64 batteries exceeds 310 hours? d) Discuss how the sample size affects the shape and variability of the sampling distribution.arrow_forward
- A biologist is investigating the effect of potential plant hormones by treating 20 stem segments. At the end of the observation period he computes the following length averages: Compound X = 1.18 Compound Y = 1.17 Based on these mean values he concludes that there are no treatment differences. 1) Are you satisfied with his conclusion? Why or why not? 2) If he asked you for help in analyzing these data, what statistical method would you suggest that he use to come to a meaningful conclusion about his data and why? 3) Are there any other questions you would ask him regarding his experiment, data collection, and analysis methods?arrow_forwardBusinessarrow_forwardWhat is the solution and answer to question?arrow_forward
- To: [Boss's Name] From: Nathaniel D Sain Date: 4/5/2025 Subject: Decision Analysis for Business Scenario Introduction to the Business Scenario Our delivery services business has been experiencing steady growth, leading to an increased demand for faster and more efficient deliveries. To meet this demand, we must decide on the best strategy to expand our fleet. The three possible alternatives under consideration are purchasing new delivery vehicles, leasing vehicles, or partnering with third-party drivers. The decision must account for various external factors, including fuel price fluctuations, demand stability, and competition growth, which we categorize as the states of nature. Each alternative presents unique advantages and challenges, and our goal is to select the most viable option using a structured decision-making approach. Alternatives and States of Nature The three alternatives for fleet expansion were chosen based on their cost implications, operational efficiency, and…arrow_forwardBusinessarrow_forwardWhy researchers are interested in describing measures of the center and measures of variation of a data set?arrow_forward
- WHAT IS THE SOLUTION?arrow_forwardThe following ordered data list shows the data speeds for cell phones used by a telephone company at an airport: A. Calculate the Measures of Central Tendency from the ungrouped data list. B. Group the data in an appropriate frequency table. C. Calculate the Measures of Central Tendency using the table in point B. 0.8 1.4 1.8 1.9 3.2 3.6 4.5 4.5 4.6 6.2 6.5 7.7 7.9 9.9 10.2 10.3 10.9 11.1 11.1 11.6 11.8 12.0 13.1 13.5 13.7 14.1 14.2 14.7 15.0 15.1 15.5 15.8 16.0 17.5 18.2 20.2 21.1 21.5 22.2 22.4 23.1 24.5 25.7 28.5 34.6 38.5 43.0 55.6 71.3 77.8arrow_forwardII Consider the following data matrix X: X1 X2 0.5 0.4 0.2 0.5 0.5 0.5 10.3 10 10.1 10.4 10.1 10.5 What will the resulting clusters be when using the k-Means method with k = 2. In your own words, explain why this result is indeed expected, i.e. why this clustering minimises the ESS map.arrow_forward
 MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman