
Videos
State the hypotheses, test statistic and the two-tailed p-value.
Make a decision for the research question “whether there is significant
Identify the issues of
Identify whether non-normality is concerned or not.
Answer to Problem 36CE
The hypotheses for the test are given below:
Null hypothesis:
The rank correlation between gasoline price and carbon dioxide emission is zero.
Alternate Hypothesis:
The rank correlation between gasoline price and carbon dioxide is greater than zero.
The test statistic and the p-value are –0.588 and 0.355 respectively.
There is a support evidence to conclude that there exists a significant correlation between gasoline price and carbon dioxide emission at 5% level of significance.
The decision is close since the rejection of null hypothesis is close to the research question “whether there is significant correlation between gasoline price and carbon dioxide emission?”
The sample size is not an issue.
The gasoline price follows normality but the carbon dioxide emission does not follow normality.
Explanation of Solution
Calculation:
The given information is that, the data shows gasoline price and carbon emissions for selected nations. The level of significance is 0.05.
The hypotheses for the test are given below:
Null hypothesis:
The rank correlation between gasoline price and carbon dioxide emission is zero.
Alternate Hypothesis:
The rank correlation between gasoline price and carbon dioxide emission is greater than zero.
Software procedure:
Step-by-step procedure to find the
- Choose MegaStat > Nonparametric Tests > Spearman Coefficient of Rank Correlation.
- In Input
range , select the cells A1:B32. - Unselect Output ranked data and Correct for ties.
- Click OK.
Output obtained from MegaStat is given below:
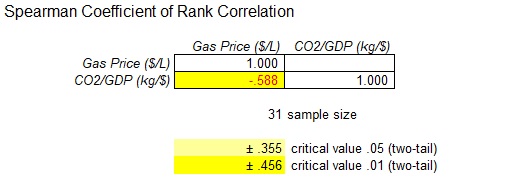
Decision Rule:
Reject the null hypothesis
Conclusion:
The absolute value of the test statistic is 0.588 and the critical value for the desired level of significance
The test statistic is greater than the critical value.
That is,
Thus, the null hypothesis is rejected.
Hence, there is a support of evidence to conclude that there exists a significant correlation between gasoline price and carbon dioxide at 5% level of significance.
Histogram for gasoline price:
Step-by-step procedure to construct a histogram using MINITAB is given below:
- Choose Basic Statistics > Graphical Summary.
- Choose Simple, and then click OK.
- In variables, enter the column of Gasoline price.
- In Confidence level, enter 95.0.
- Click OK.
Output obtained from MINITAB is given below:
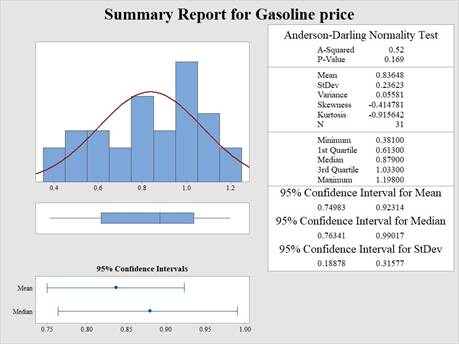
Interpretation:
The histogram appears to be left skewed since the tail is elongated towards the left than to the right side. Hence, the test of normality is recommended.
Testing the normality using Anderson Darling test:
Null hypothesis:
Alternate Hypothesis:
Decision Rule:
Reject the null hypothesis
Conclusion:
The p-value for the A-D test is 0.169 and the level of significance is 0.05.
The p-value for the A-D test is greater than the level of significance.
That is,
Thus, the null hypothesis is rejected.
Hence, there is a support of evidence to assume that gasoline follows normal distribution at 5% level of significance.
Histogram for carbon dioxide emission:
Step-by-step procedure to construct a histogram using MINITAB is given below:
- Choose Basic Statistics > Graphical Summary.
- Choose Simple, and then click OK.
- In variables, enter the column of carbon dioxide emission.
- In Confidence level, enter 95.0.
- Click OK.
Output obtained from MINITAB is given below:
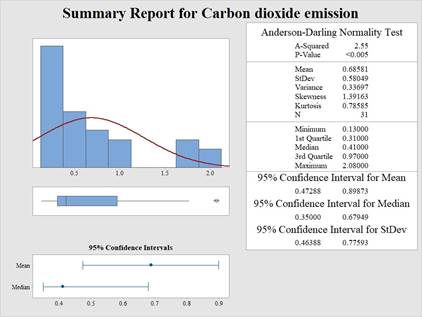
Interpretation:
The histogram appears to be right skewed since the tail is elongated towards the right than to the left side. Hence, the test of normality is recommended.
Testing the normality using Anderson Darling test:
Null hypothesis:
Alternate Hypothesis:
Decision Rule:
Reject the null hypothesis
Conclusion:
The p-value for the A-D test is lesser than 0.005 and the level of significance is 0.05.
The p-value for the A-D test is lesser than the level of significance.
That is,
Thus, the null hypothesis is rejected.
Hence, there is no support of evidence to assume that the carbon dioxide emission follows normal distribution at 5% level of significance.
Want to see more full solutions like this?
Chapter 16 Solutions
Loose-leaf For Applied Statistics In Business And Economics


- The following ordered data list shows the data speeds for cell phones used by a telephone company at an airport: A. Calculate the Measures of Central Tendency from the ungrouped data list. B. Group the data in an appropriate frequency table. C. Calculate the Measures of Central Tendency using the table in point B. 0.8 1.4 1.8 1.9 3.2 3.6 4.5 4.5 4.6 6.2 6.5 7.7 7.9 9.9 10.2 10.3 10.9 11.1 11.1 11.6 11.8 12.0 13.1 13.5 13.7 14.1 14.2 14.7 15.0 15.1 15.5 15.8 16.0 17.5 18.2 20.2 21.1 21.5 22.2 22.4 23.1 24.5 25.7 28.5 34.6 38.5 43.0 55.6 71.3 77.8arrow_forwardII Consider the following data matrix X: X1 X2 0.5 0.4 0.2 0.5 0.5 0.5 10.3 10 10.1 10.4 10.1 10.5 What will the resulting clusters be when using the k-Means method with k = 2. In your own words, explain why this result is indeed expected, i.e. why this clustering minimises the ESS map.arrow_forwardwhy the answer is 3 and 10?arrow_forward
- PS 9 Two films are shown on screen A and screen B at a cinema each evening. The numbers of people viewing the films on 12 consecutive evenings are shown in the back-to-back stem-and-leaf diagram. Screen A (12) Screen B (12) 8 037 34 7 6 4 0 534 74 1645678 92 71689 Key: 116|4 represents 61 viewers for A and 64 viewers for B A second stem-and-leaf diagram (with rows of the same width as the previous diagram) is drawn showing the total number of people viewing films at the cinema on each of these 12 evenings. Find the least and greatest possible number of rows that this second diagram could have. TIP On the evening when 30 people viewed films on screen A, there could have been as few as 37 or as many as 79 people viewing films on screen B.arrow_forwardQ.2.4 There are twelve (12) teams participating in a pub quiz. What is the probability of correctly predicting the top three teams at the end of the competition, in the correct order? Give your final answer as a fraction in its simplest form.arrow_forwardThe table below indicates the number of years of experience of a sample of employees who work on a particular production line and the corresponding number of units of a good that each employee produced last month. Years of Experience (x) Number of Goods (y) 11 63 5 57 1 48 4 54 5 45 3 51 Q.1.1 By completing the table below and then applying the relevant formulae, determine the line of best fit for this bivariate data set. Do NOT change the units for the variables. X y X2 xy Ex= Ey= EX2 EXY= Q.1.2 Estimate the number of units of the good that would have been produced last month by an employee with 8 years of experience. Q.1.3 Using your calculator, determine the coefficient of correlation for the data set. Interpret your answer. Q.1.4 Compute the coefficient of determination for the data set. Interpret your answer.arrow_forward
- Can you answer this question for mearrow_forwardTechniques QUAT6221 2025 PT B... TM Tabudi Maphoru Activities Assessments Class Progress lIE Library • Help v The table below shows the prices (R) and quantities (kg) of rice, meat and potatoes items bought during 2013 and 2014: 2013 2014 P1Qo PoQo Q1Po P1Q1 Price Ро Quantity Qo Price P1 Quantity Q1 Rice 7 80 6 70 480 560 490 420 Meat 30 50 35 60 1 750 1 500 1 800 2 100 Potatoes 3 100 3 100 300 300 300 300 TOTAL 40 230 44 230 2 530 2 360 2 590 2 820 Instructions: 1 Corall dawn to tha bottom of thir ceraan urina se se tha haca nariad in archerca antarand cubmit Q Search ENG US 口X 2025/05arrow_forwardThe table below indicates the number of years of experience of a sample of employees who work on a particular production line and the corresponding number of units of a good that each employee produced last month. Years of Experience (x) Number of Goods (y) 11 63 5 57 1 48 4 54 45 3 51 Q.1.1 By completing the table below and then applying the relevant formulae, determine the line of best fit for this bivariate data set. Do NOT change the units for the variables. X y X2 xy Ex= Ey= EX2 EXY= Q.1.2 Estimate the number of units of the good that would have been produced last month by an employee with 8 years of experience. Q.1.3 Using your calculator, determine the coefficient of correlation for the data set. Interpret your answer. Q.1.4 Compute the coefficient of determination for the data set. Interpret your answer.arrow_forward
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
Big Ideas Math A Bridge To Success Algebra 1: Stu...AlgebraISBN:9781680331141Author:HOUGHTON MIFFLIN HARCOURTPublisher:Houghton Mifflin Harcourt
 Algebra: Structure And Method, Book 1AlgebraISBN:9780395977224Author:Richard G. Brown, Mary P. Dolciani, Robert H. Sorgenfrey, William L. ColePublisher:McDougal Littell
Algebra: Structure And Method, Book 1AlgebraISBN:9780395977224Author:Richard G. Brown, Mary P. Dolciani, Robert H. Sorgenfrey, William L. ColePublisher:McDougal Littell