
Concept explainers
Videos
(a)
To Explain: the reason of linear model is not appropriate.
(a)
Explanation of Solution
Given:
| Speed (mph) | Stopping Distances (ft) |
| 20 | 64, 62, 59 |
| 30 | 114, 118, 105 |
| 40 | 153, 171, 165 |
| 50 | 231, 203, 238 |
| 60 | 317, 321, 276 |
Graph:
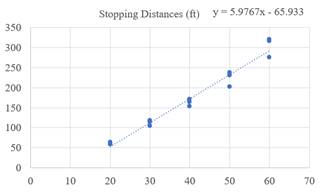
Suppose that both the explanatory variable and the response variable are speed (mph) and stopping distance (ft). The linearity of the
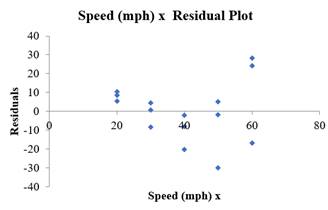
By seeing the shape of the drawn plot, there is curved pattern, which is violating the straight the sufficient condition. Therefore, the linear equation
(b)
To find: the re-express the data to straighten the scatter plot.
(b)
Explanation of Solution
Given:
| Speed (mph) | Stopping Distances (ft) |
| 20 | 64, 62, 59 |
| 30 | 114, 118, 105 |
| 40 | 153, 171, 165 |
| 50 | 231, 203, 238 |
| 60 | 317, 321, 276 |
Calculation:
In Part (a), it can observe that there is no linearity in the results. It is important to make it linear in order toTransform the data for the Stopping Distance response variable into a square root form. Then there's the
SQRT (Stopping Distance) appears like a new response variable.
Below, the data is mention:
| Speed (mph) x | Stopping Distances (ft) | sqrt (Stopping Distances) |
| 20 | 64 | 8 |
| 20 | 62 | 7.874007874 |
| 20 | 59 | 7.681145748 |
| 30 | 114 | 10.67707825 |
| 30 | 118 | 10.86278049 |
| 30 | 105 | 10.24695077 |
| 40 | 153 | 12.36931688 |
| 40 | 171 | 13.07669683 |
| 40 | 165 | 12.84523258 |
| 50 | 231 | 15.19868415 |
| 50 | 203 | 14.24780685 |
| 50 | 238 | 15.42724862 |
| 60 | 317 | 17.80449381 |
| 60 | 321 | 17.91647287 |
| 60 | 276 | 16.61324773 |
Graph:
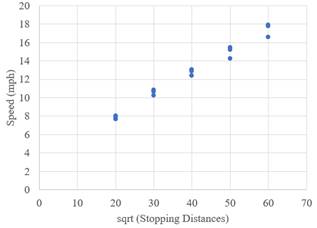
It may conclude from the scatter plot that this is a good model to fit in. it can tell from this, the square root of the distance linearizes the diagram.
(c)
To construct: the appropriate model.
(c)
Answer to Problem 15E
Explanation of Solution
| Speed (mph) | Stopping Distances (ft) |
| 20 | 64, 62, 59 |
| 30 | 114, 118, 105 |
| 40 | 153, 171, 165 |
| 50 | 231, 203, 238 |
| 60 | 317, 321, 276 |
Calculation:
| Coefficients | Standard Error | t Stat | |
| Intercept | 3.303404005 | 0.347689827 | 9.501008521 |
| Speed (mph) x | 0.235483506 | 0.008195128 | 28.73457391 |
| Regression Statistics | |
| Multiple R | 0.992219418 |
| R Square | 0.984499373 |
| Adjusted R Square | 0.983307017 |
| Standard Error | 0.448865636 |
| Observations | 15 |
Predicted regression equation
(d)
To Calculate:the stopping distance for a car travelling 55 mph.
(d)
Answer to Problem 15E
263.251
Explanation of Solution
Given:
Formula used:
Calculation:
(e)
To Calculate:the stopping distance for a car travelling 70 mph.
(e)
Explanation of Solution
Given:
Formula used:
Calculation:
(f)
To find: the confidence that place in these predictions.
(f)
Explanation of Solution
The results got in part (c), the coefficient of determination is
Chapter 10 Solutions
Stats: Modeling the World Nasta Edition Grades 9-12
Additional Math Textbook Solutions
A First Course in Probability (10th Edition)
Introductory Statistics
College Algebra (7th Edition)
Elementary Statistics (13th Edition)
University Calculus: Early Transcendentals (4th Edition)
Elementary Statistics: Picturing the World (7th Edition)


- Consider the state space model X₁ = §Xt−1 + Wt, Yt = AX+Vt, where Xt Є R4 and Y E R². Suppose we know the covariance matrices for Wt and Vt. How many unknown parameters are there in the model?arrow_forwardBusiness Discussarrow_forwardYou want to obtain a sample to estimate the proportion of a population that possess a particular genetic marker. Based on previous evidence, you believe approximately p∗=11% of the population have the genetic marker. You would like to be 90% confident that your estimate is within 0.5% of the true population proportion. How large of a sample size is required?n = (Wrong: 10,603) Do not round mid-calculation. However, you may use a critical value accurate to three decimal places.arrow_forward
- 2. [20] Let {X1,..., Xn} be a random sample from Ber(p), where p = (0, 1). Consider two estimators of the parameter p: 1 p=X_and_p= n+2 (x+1). For each of p and p, find the bias and MSE.arrow_forward1. [20] The joint PDF of RVs X and Y is given by xe-(z+y), r>0, y > 0, fx,y(x, y) = 0, otherwise. (a) Find P(0X≤1, 1arrow_forward4. [20] Let {X1,..., X} be a random sample from a continuous distribution with PDF f(x; 0) = { Axe 5 0, x > 0, otherwise. where > 0 is an unknown parameter. Let {x1,...,xn} be an observed sample. (a) Find the value of c in the PDF. (b) Find the likelihood function of 0. (c) Find the MLE, Ô, of 0. (d) Find the bias and MSE of 0.arrow_forward3. [20] Let {X1,..., Xn} be a random sample from a binomial distribution Bin(30, p), where p (0, 1) is unknown. Let {x1,...,xn} be an observed sample. (a) Find the likelihood function of p. (b) Find the MLE, p, of p. (c) Find the bias and MSE of p.arrow_forwardGiven the sample space: ΩΞ = {a,b,c,d,e,f} and events: {a,b,e,f} A = {a, b, c, d}, B = {c, d, e, f}, and C = {a, b, e, f} For parts a-c: determine the outcomes in each of the provided sets. Use proper set notation. a. (ACB) C (AN (BUC) C) U (AN (BUC)) AC UBC UCC b. C. d. If the outcomes in 2 are equally likely, calculate P(AN BNC).arrow_forwardSuppose a sample of O-rings was obtained and the wall thickness (in inches) of each was recorded. Use a normal probability plot to assess whether the sample data could have come from a population that is normally distributed. Click here to view the table of critical values for normal probability plots. Click here to view page 1 of the standard normal distribution table. Click here to view page 2 of the standard normal distribution table. 0.191 0.186 0.201 0.2005 0.203 0.210 0.234 0.248 0.260 0.273 0.281 0.290 0.305 0.310 0.308 0.311 Using the correlation coefficient of the normal probability plot, is it reasonable to conclude that the population is normally distributed? Select the correct choice below and fill in the answer boxes within your choice. (Round to three decimal places as needed.) ○ A. Yes. The correlation between the expected z-scores and the observed data, , exceeds the critical value, . Therefore, it is reasonable to conclude that the data come from a normal population. ○…arrow_forwardding question ypothesis at a=0.01 and at a = 37. Consider the following hypotheses: 20 Ho: μ=12 HA: μ12 Find the p-value for this hypothesis test based on the following sample information. a. x=11; s= 3.2; n = 36 b. x = 13; s=3.2; n = 36 C. c. d. x = 11; s= 2.8; n=36 x = 11; s= 2.8; n = 49arrow_forward13. A pharmaceutical company has developed a new drug for depression. There is a concern, however, that the drug also raises the blood pressure of its users. A researcher wants to conduct a test to validate this claim. Would the manager of the pharmaceutical company be more concerned about a Type I error or a Type II error? Explain.arrow_forwardFind the z score that corresponds to the given area 30% below z.arrow_forwardarrow_back_iosSEE MORE QUESTIONSarrow_forward_ios
 MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc
MATLAB: An Introduction with ApplicationsStatisticsISBN:9781119256830Author:Amos GilatPublisher:John Wiley & Sons Inc Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning
Probability and Statistics for Engineering and th...StatisticsISBN:9781305251809Author:Jay L. DevorePublisher:Cengage Learning Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning
Statistics for The Behavioral Sciences (MindTap C...StatisticsISBN:9781305504912Author:Frederick J Gravetter, Larry B. WallnauPublisher:Cengage Learning Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON
Elementary Statistics: Picturing the World (7th E...StatisticsISBN:9780134683416Author:Ron Larson, Betsy FarberPublisher:PEARSON The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman
The Basic Practice of StatisticsStatisticsISBN:9781319042578Author:David S. Moore, William I. Notz, Michael A. FlignerPublisher:W. H. Freeman Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman
Introduction to the Practice of StatisticsStatisticsISBN:9781319013387Author:David S. Moore, George P. McCabe, Bruce A. CraigPublisher:W. H. Freeman