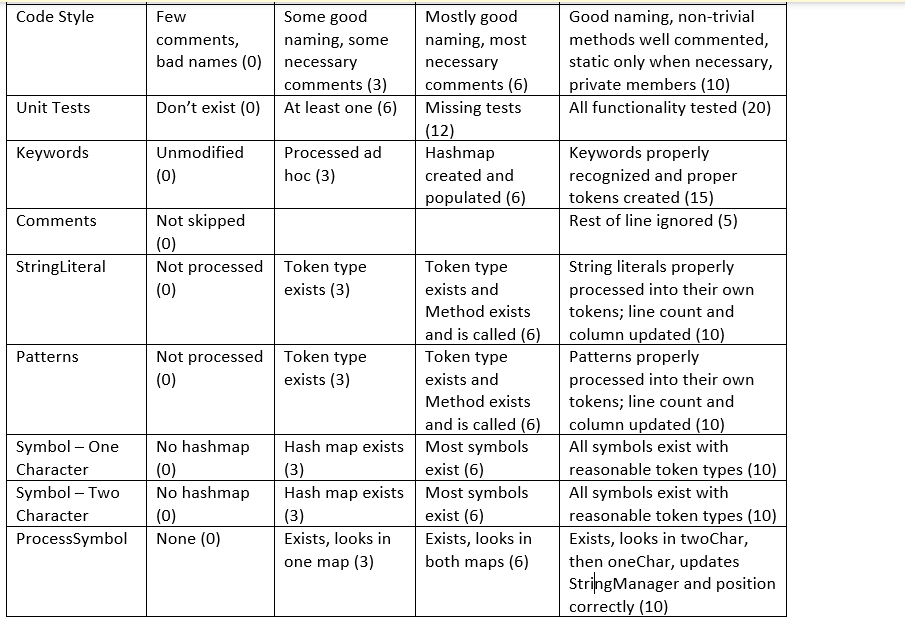
Code Style Unit Tests Keywords Comments StringLiteral Patterns Symbol - One Character Symbol - Two Character ProcessSymbol Some good naming, some necessary comments (3) Don't exist (0) At least one (6) Few comments, bad names (0) Unmodified (0) Not skipped (0) Not processed (0) Processed ad hoc (3) No hashmap (0) No hashmap (0) None (0) Token type exists (3) Not processed Token type (0) exists (3) Mostly good naming, most necessary comments (6) Missing tests (12) Hashmap created and populated (6) Token type exists and Method exists and is called (6) Token type exists and Method exists and is called (6) Hash map exists Most symbols (3) exist (6) Hash map exists Most symbols (3) exist (6) Exists, looks in one map (3) Exists, looks in both maps (6) Good naming, non-trivial methods well commented, static only when necessary, private members (10) All functionality tested (20) Keywords properly recognized and proper tokens created (15) Rest of line ignored (5) String literals properly processed into their own tokens; line count and column updated (10) Patterns properly processed into their own tokens; line count and column updated (10) All symbols exist with reasonable token types (10) All symbols exist with reasonable token types (10) Exists, looks in twoChar, then oneChar, updates StringManager and position correctly (10)
Oh no! Our experts couldn't answer your question.
Don't worry! We won't leave you hanging. Plus, we're giving you back one question for the inconvenience.
Java Code: For Lexer.java
Make a HashMap of <String, TokenType> in your Lex class. Below is a list of the keywords that you need. Make token types and populate the hash map in your constructor (I would make a helper method that the constructor calls).
while, if, do, for, break, continue, else, return, BEGIN, END, print, printf, next, in, delete, getline, exit, nextfile, function
Modify “ProcessWord” so that it checks the hash map for known words and makes a token specific to the word with no value if the word is in the hash map, but WORD otherwise.
For example,
Input: for while hello do
Output: FOR WHILE WORD(hello) DO
In your loop in Lex, we need to deal with comments. Comments in AWK start with # and go to the end of the line (like // comments in Java). When you encounter a #, loop to the end of the line. No need to update line number or line index, because we aren’t going to output any tokens for comments.
You are familiar with string literals in Java ( String foo = “hello world”; ) AWK has them as well. Make a token type for string literals. In Lex, when you encounter a “, call a new method (I called it HandleStringLiteral() ) that reads up through the matching “ and creates a string literal token ( STRINGLITERAL(hello world) ). Be careful of two things: make sure that an empty string literal ( “” ) works and make sure to deal with escaped “ (String quote = “She said, \”hello there\” and then she left.”;)
AWK builds in regular expressions as a literal. “Real” AWK uses slashes for their patterns: (example: /.*/ ). That makes the parser much harder since we use / for division. Instead, we will use the backtick (` - next to the “1” on your keyboard). The logic for this is very similar to StringLiteral (it just uses ` instead of “ ). Make a new token type, a new method (HandlePattern) and call it from Lex when you encounter a backtick.
The last thing that we need to deal with in our lexer is symbols. Most of these will be familiar from Java, but a few I will detail a bit more. We will be using two different hash maps – one for two-character symbols (like ==, &&, ++) and one for one character symbols (like +, -, $). Why? Well, some two-character symbols start with characters that are also symbols (for example, + and +=). We need to prioritize the += and only match + if it is not a +=.
Two-character symbols:
>= ++ -- <= == != ^= %= *= /= += -= !~ && >> ||
^ is the symbol in AWK for exponents (5^3 == 125).
~ is the symbol in AWK for match, so !~ is “does not match”
>> is the symbol in AWK (and BASH) for append.
Create token types and a hash map for these symbols.
Next create the token types and the hash maps for the single character symbols (I used String, not char):
{ } [ ] ( ) $ ~ = < > ! + ^ - ? : * / % ; \n | ,
Create a method called “ProcessSymbol” – it should use PeekString to get 2 characters and look them up in the two-character hash map. If it exists, make the appropriate token and return it. Otherwise, use PeekString to get a 1 character string. Look that up in the one-character hash map. If it exists, create the appropriate token and return it. Don’t forget to update the position in the line. If no symbol is found, return null. Call ProcessSymbol in your lex() method. If it returns a value, add the token to the token list.
Make sure all the functionality of the unit test are tested and show the full lexer.java with main.java, token.java, & stringhandler.java with the screenshot of the output. Attached is checklist.