
Concept explainers
Videos
The paper “Sociochemosensory and Emotional
One of the three shirts had been worn by the subject’s roommate. The subject was asked to identify the shirt worn by her roommate. This process was then repeated with another three shirts, and the number of times out of the two trials that the subject correctly identified the shirt worn by her roommate was recorded. The resulting data are summarized in the accompanying table.
![Chapter 12.1, Problem 10E, The paper Sociochemosensory and Emotional Functions (Psychological Science [2009]: 11181124)](https://content.bartleby.com/tbms-images/9781337793612/Chapter-12/images/93612-12.1-10e-question-digital_image_001.png)
- a. Can a person identify her roommate by smell? If not, the data from the experiment should be consistent with what we would have expected to see if subjects were just guessing on each trial. That is, we would expect that the probability of selecting the correct shirt would be 1/3 on each of the two trials.
Calculate the proportions of the time we would expect to see 0, 1, and 2 correct identifications if subjects are just guessing. (Hint: 0 correct identifications occurs if the first trial is incorrect and the second trial is incorrect.)
- b. Use the three proportions calculated in Part (a) to carry out a test to determine if the numbers of correct identifications by the students in this study are significantly different from what would have been expected by guessing. Use α = 0.05. (Note: One of the expected counts is just a bit less than 5. For purposes of this exercise, assume that it is OK to proceed with a goodness-of-fit test.)
a.
Calculate the proportion of time expected to see 0, 1, and 2 correct identifications if subjects are just guessing.
Answer to Problem 10E
When the subjects are just guessing, the proportion of time expected to see 0, 1, and 2 correct identifications are
Explanation of Solution
Calculation:
It is given that if subjects were just guessing on each trial, the probability of selecting the correct shirt would be
Thus, the probability of selecting the wrong shirt is
The proportion of 0 correct identifications expected in two trials is shown below.
The proportion of 1 correct identifications expected in two trials is shown below.
The proportion of 2 correct identifications expected in two trials is shown below
b.
Test whether the numbers of correct identifications by the students in this study are significantly different from what would have been expected by guessing at 0.05 level of significance.
Answer to Problem 10E
The numbers of correct identifications by the students in this study are significantly different from those that would have been expected by guessing.
Explanation of Solution
The given data represents the number of correct identifications of shirt worn by her roommate in two trials.
The expected counts can be calculated using the formula,
| Number of correct identification | Observed Frequency | Expected counts |
| 0 | 21 | |
| 1 | 10 | |
| 2 | 13 | |
| Total | 44 | 44 |
The nine step hypotheses testing procedure to test goodness-of-fit is given below.
1. The proportion of correct identifications are
2. Null hypothesis:
3. Alternative hypothesis:
4. Significance level:
5. Test statistic:
6. Assumptions:
- Randomness assumption is not necessary, as the question is only to test whether the observed counts differ from expected by guessing.
- From the table above, it is observed that one of the expected counts is a little less than 5. However, as per the instruction, the goodness-of-fit test can be done.
7. Calculation:
Software procedure:
Step-by-step procedure to obtain the test statistics and P-value using the MINITAB software:
- Choose Stat > Tables > Chi-Square Goodness-of-Fit Test (One Variable).
- In Observed counts, enter the column of Observed count.
- In Category names, enter the column of Number of correct identification.
- Under Test, select the column of Proportion in Proportions specified by historical counts.
- Click OK.
Output using the MINITAB software is given below:
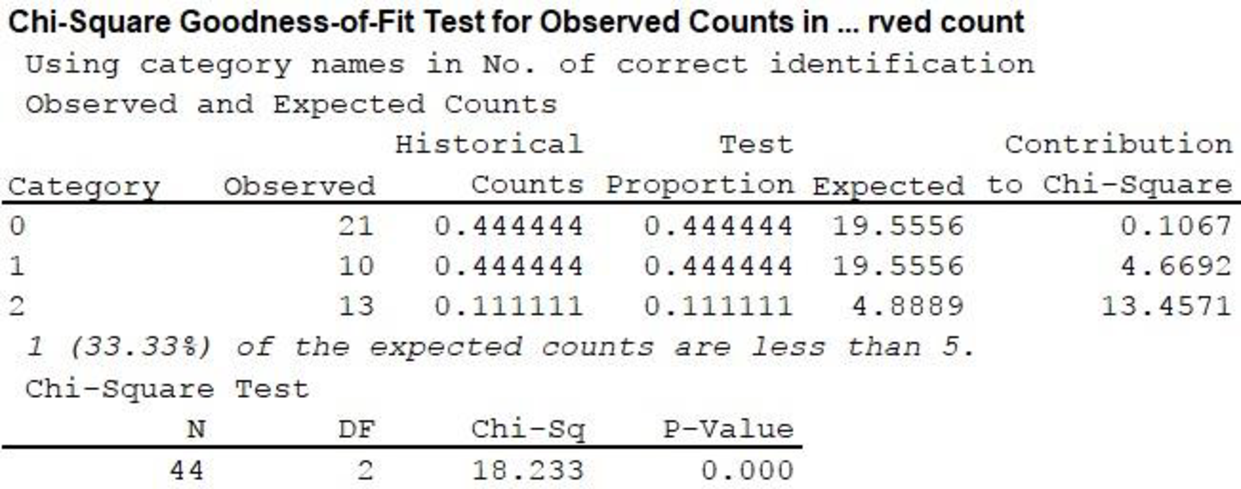
From the output,
8. P-value:
From the MINITAB output,
9. Conclusion:
Decision rule:
- If P-value is less than or equal to the level of significance, reject the null hypothesis.
- Otherwise fail to reject the null hypothesis.
Conclusion:
Here the level of significance is 0.05.
Here, P-value is less than the level of significance.
That is,
Therefore, reject the null hypothesis. Hence, the numbers of correct identifications by the students in this study are significantly different from those that would have been expected by guessing.
Want to see more full solutions like this?
Chapter 12 Solutions
Introduction To Statistics And Data Analysis


- PEER REPLY 1: Choose a classmate's Main Post. 1. Indicate a range of values for the independent variable (x) that is reasonable based on the data provided. 2. Explain what the predicted range of dependent values should be based on the range of independent values.arrow_forwardIn a company with 80 employees, 60 earn $10.00 per hour and 20 earn $13.00 per hour. Is this average hourly wage considered representative?arrow_forwardThe following is a list of questions answered correctly on an exam. Calculate the Measures of Central Tendency from the ungrouped data list. NUMBER OF QUESTIONS ANSWERED CORRECTLY ON AN APTITUDE EXAM 112 72 69 97 107 73 92 76 86 73 126 128 118 127 124 82 104 132 134 83 92 108 96 100 92 115 76 91 102 81 95 141 81 80 106 84 119 113 98 75 68 98 115 106 95 100 85 94 106 119arrow_forward
- The following ordered data list shows the data speeds for cell phones used by a telephone company at an airport: A. Calculate the Measures of Central Tendency using the table in point B. B. Are there differences in the measurements obtained in A and C? Why (give at least one justified reason)? 0.8 1.4 1.8 1.9 3.2 3.6 4.5 4.5 4.6 6.2 6.5 7.7 7.9 9.9 10.2 10.3 10.9 11.1 11.1 11.6 11.8 12.0 13.1 13.5 13.7 14.1 14.2 14.7 15.0 15.1 15.5 15.8 16.0 17.5 18.2 20.2 21.1 21.5 22.2 22.4 23.1 24.5 25.7 28.5 34.6 38.5 43.0 55.6 71.3 77.8arrow_forwardIn a company with 80 employees, 60 earn $10.00 per hour and 20 earn $13.00 per hour. a) Determine the average hourly wage. b) In part a), is the same answer obtained if the 60 employees have an average wage of $10.00 per hour? Prove your answer.arrow_forwardThe following ordered data list shows the data speeds for cell phones used by a telephone company at an airport: A. Calculate the Measures of Central Tendency from the ungrouped data list. B. Group the data in an appropriate frequency table. 0.8 1.4 1.8 1.9 3.2 3.6 4.5 4.5 4.6 6.2 6.5 7.7 7.9 9.9 10.2 10.3 10.9 11.1 11.1 11.6 11.8 12.0 13.1 13.5 13.7 14.1 14.2 14.7 15.0 15.1 15.5 15.8 16.0 17.5 18.2 20.2 21.1 21.5 22.2 22.4 23.1 24.5 25.7 28.5 34.6 38.5 43.0 55.6 71.3 77.8arrow_forward
- Businessarrow_forwardhttps://www.hawkeslearning.com/Statistics/dbs2/datasets.htmlarrow_forwardNC Current Students - North Ce X | NC Canvas Login Links - North ( X Final Exam Comprehensive x Cengage Learning x WASTAT - Final Exam - STAT → C webassign.net/web/Student/Assignment-Responses/submit?dep=36055360&tags=autosave#question3659890_9 Part (b) Draw a scatter plot of the ordered pairs. N Life Expectancy Life Expectancy 80 70 600 50 40 30 20 10 Year of 1950 1970 1990 2010 Birth O Life Expectancy Part (c) 800 70 60 50 40 30 20 10 1950 1970 1990 W ALT 林 $ # 4 R J7 Year of 2010 Birth F6 4+ 80 70 60 50 40 30 20 10 Year of 1950 1970 1990 2010 Birth Life Expectancy Ox 800 70 60 50 40 30 20 10 Year of 1950 1970 1990 2010 Birth hp P.B. KA & 7 80 % 5 H A B F10 711 N M K 744 PRT SC ALT CTRLarrow_forward
- Harvard University California Institute of Technology Massachusetts Institute of Technology Stanford University Princeton University University of Cambridge University of Oxford University of California, Berkeley Imperial College London Yale University University of California, Los Angeles University of Chicago Johns Hopkins University Cornell University ETH Zurich University of Michigan University of Toronto Columbia University University of Pennsylvania Carnegie Mellon University University of Hong Kong University College London University of Washington Duke University Northwestern University University of Tokyo Georgia Institute of Technology Pohang University of Science and Technology University of California, Santa Barbara University of British Columbia University of North Carolina at Chapel Hill University of California, San Diego University of Illinois at Urbana-Champaign National University of Singapore McGill…arrow_forwardName Harvard University California Institute of Technology Massachusetts Institute of Technology Stanford University Princeton University University of Cambridge University of Oxford University of California, Berkeley Imperial College London Yale University University of California, Los Angeles University of Chicago Johns Hopkins University Cornell University ETH Zurich University of Michigan University of Toronto Columbia University University of Pennsylvania Carnegie Mellon University University of Hong Kong University College London University of Washington Duke University Northwestern University University of Tokyo Georgia Institute of Technology Pohang University of Science and Technology University of California, Santa Barbara University of British Columbia University of North Carolina at Chapel Hill University of California, San Diego University of Illinois at Urbana-Champaign National University of Singapore…arrow_forwardA company found that the daily sales revenue of its flagship product follows a normal distribution with a mean of $4500 and a standard deviation of $450. The company defines a "high-sales day" that is, any day with sales exceeding $4800. please provide a step by step on how to get the answers in excel Q: What percentage of days can the company expect to have "high-sales days" or sales greater than $4800? Q: What is the sales revenue threshold for the bottom 10% of days? (please note that 10% refers to the probability/area under bell curve towards the lower tail of bell curve) Provide answers in the yellow cellsarrow_forward
 Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill
Glencoe Algebra 1, Student Edition, 9780079039897...AlgebraISBN:9780079039897Author:CarterPublisher:McGraw Hill Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL
Holt Mcdougal Larson Pre-algebra: Student Edition...AlgebraISBN:9780547587776Author:HOLT MCDOUGALPublisher:HOLT MCDOUGAL